问题:想要在本机或者一台服务器上访问另外一台服务器数据库中的表,可以通过建立链接服务器方式实现.
步骤:1.建立链接服务器

2.设置链接服务器名称(常规->选择SQL Server->输入连接服务器名称)

3.设置连接的服务器和密码(安全性->使用此安全上下文建立连接->填写账号密码)

4.访问方法
SELECT * FROM 服务器名.数据库.dbo.表名
SELECT * FROM qsbndb3.QSBN.dbo.tb_book
问题:想要在本机或者一台服务器上访问另外一台服务器数据库中的表,可以通过建立链接服务器方式实现.
步骤:1.建立链接服务器
2.设置链接服务器名称(常规->选择SQL Server->输入连接服务器名称)
3.设置连接的服务器和密码(安全性->使用此安全上下文建立连接->填写账号密码)
4.访问方法
SELECT * FROM 服务器名.数据库.dbo.表名
SELECT * FROM qsbndb3.QSBN.dbo.tb_book
sqlservr 应用程序可以在命令提示符下启动,停止,暂停和继续 Microsoft SQL Server 的实例.
语法:
sqlservr [-sinstance_name] [-c] [-dmaster_path] [-f]
[-eerror_log_path] [-lmaster_log_path] [-m]
[-n] [-Ttrace#] [-v] [-x] [-gnumber] [-h]
参数:
-s instance_name
指定要连接到的 SQL Server 实例.如果未指定命名实例,sqlservr 将启动 SQL Server 的默认实例.
重要提示:启动 SQL Server 实例时,必须在该实例的相应目录中使用 sqlservr 应用程序.对于默认实例,从/MSSQL/Binn 目录运行 sqlservr.对于命名实例,在 /MSSQL$instance_name/Binn 目录运行sqlservr.
-c
指示独立于 Windows 服务控制管理器启动 SQL Server 实例.从命令提示符下启动 SQL Server 时可使用此选项,以缩短 SQL Server 的启动时间.
注意:使用此选项时,将无法通过使用 SQL Server 服务管理器或 net stop 命令停止 SQL Server.如果注销计算机,则 SQL Server 将停止.
-dmaster_path
指出 master 数据库文件的完全限定路径.在 -d 和 master_path 之间没有空格.如果没有提供此选项,则使用现有的注册表参数.
-f
以最小配置启动 SQL Server 实例.在配置值的设置(如过度分配内存)妨碍服务器启动时,这非常有用.
-e error_log_path
指示错误日志文件的完全限定路径.如果不指定路径,则默认实例的默认位置是 <Drive>:/Program Files/Microsoft SQL Server/MSSQL/Log/Errorlog,命名实例的默认位置是 <Drive>:/Program Files/Microsoft SQL Server/MSSQL$instance_name/Log/Errorlog.在 -e 和 error_log_path之间没有空格.
-l master_log_path
指示 master 数据库事务日志文件的完全限定路径.在 -l 和 master_log_path 之间没有空格.
-m
指示以单用户模式启动 SQL Server 实例.如果以单用户模式启动 SQL Server,则只有一个用户可以连接.确保将已完成事务定期从磁盘缓存写入数据库设备的 CHECKPOINT 机制将不启动.通常情况下,在遇到需要修复系统数据库这样的问题时才使用该选项.启用 sp_configure allow updates 选项.默认情况下,allow updates 被禁用.
-n
用于启动 SQL Server 的命名实例.如果不设置 -s 参数,则尝试启动默认实例.必须在命令提示符下切换到实例相应的 BINN 目录,然后才能启动 sqlservr.exe.例如,如果 Instance1 为其二进制文件使用/mssql$Instance1,则用户必须位于 /mssql$Instance1/binn 目录中才能启动 sqlservr.exe -s instance1.如果用 -n 选项启动 SQL Server 实例,则最好也使用 -e 选项,否则将不会记录 SQL Server事件.
-T trace#
指示 SQL Server 实例启动时,指定的跟踪标志 (trace#) 应同时生效.跟踪标记用于以非标准行为启动服务器.有关详细信息,请参阅跟踪标志 (Transact-SQL).
重要提示:指定跟踪标志时,请使用 -T 来传递跟踪标志号.SQL Server 接受小写的 t (-t);但是 -t 通常用于设置 SQL Server 支持工程师所需的其他内部跟踪标志.
-v
显示服务器的版本号.
-x
不保留 CPU 时间和高速缓存命中率统计信息.可获得最大性能.
-g memory_to_reserve
指定 SQL Server 为位于 SQL Server 进程中但在 SQL Server 内存池之外的内存分配保留的内存整数量(MB).内存池以外的内存是指 SQL Server 用于加载诸如下列项目的区域:扩展过程 .dll 文件,分布式查询引用的 OLE DB 访问接口以及 Transact-SQL 语句中引用的自动化对象.默认值为 256 MB.
使用此选项可帮助优化内存分配,但仅限于物理内存超过操作系统设置的应用程序可用虚拟内存限制时.如果 SQL Server 的内存使用要求异乎寻常,并且 SQL Server 进程的虚拟地址空间全都在使用,那么对于这样的大内存配置适合使用此选项.对此选项的不当使用会导致 SQL Server 实例无法启动或遇到运行时错误.
除非在 SQL Server 错误日志中看到下列任何警告,否则应使用 -g 参数的默认值:
这些消息可能指示 SQL Server 尝试释放部分 SQL Server 内存池空间,以便为扩展存储过程 .dll 文件或自动化对象等项留出空间.在这种情况下,可以考虑增加由 -g 开关保留的内存量.
使用低于默认值的值可以增加缓冲池和线程堆栈可用的内存量;在不使用很多扩展存储过程,分布式查询或自动化对象的系统中,这种方法可提高需要大量内存的工作负荷的性能.
-h
对 32 位 SQL Server 启用 AWE 时为热添加内存元数据保留虚拟内存地址空间.需要为具有 32 位 AWE 的热添加内存设置该选项,但将占用大约 0.5GB 的虚拟地址空间,并会增加内存优化的难度.对于 64 位 SQL Server,不是必需项.
备注:
多数情况下,sqlservr.exe 程序只用于故障排除或主要维护.在命令提示符下使用 sqlservr.exe 启动 SQL Server 时,SQL Server 不作为服务启动,因此无法使用 net 命令停止 SQL Server.用户可以连接到 SQL Server,但 SQL Server 工具将显示服务的状态,以便 SQL Server 配置管理器正确指示服务已停止.SQL Server Management Studio 可以与服务器连接,但它也可以指示服务已停止
在分离和附加数据库时可以使用sp_detach_db,sp_attach_db和sp_attach_single_file_db系统存储过程,这三个存储过程对于SQL Server数据库管理员执行以下的任务是非常方便的:
1.使用sp_detach_db将数据库从一个服务器分离;
2.使用sp_attach_db系统存储过程直接将.mdf和.ldf文件附加到数据库服务器;
3.使用sp_attach_single_file_db系统存储过程只附加.mdf文件;
尽管它们对于SQL Server数据库管理员是很有用的,但是在使用这两个存储过程时是有一些限制的,如:
1.不能附加多个日志文件;
2.不能附加16个以上的文件;
在SQL Server 2008中,微软宣布上面的系统存储过程将在未来的版本中被废弃.而在“CREATE DATABASE”SQL语句中添加了一个从句”FOR ATTACH“.并建议应该使用“CREATE DATABASE database_name FOR ATTACH“语句
下面介绍使用”FOR ATTACH“语句的用法,以克服在使用sp_attach_db和sp_attach_single_file_db时要面临的限制.
1.创建实例数据库
2.使用sp_detach_db分离该数据库并使用sp_attach_db将它重新附加
3.使用“CREATE DATABASE database_name FOR ATTACH”语句附加数据库
4.分离数据库并删除日志(.ldf)文件
5.使用sp_attach_single_file_db附加.mdf文件
6.删除日志文件,使用“CREATE DATABASE database_name FOR ATTACH_REBUILD_LOG“附加数据库
上网查了一下,很多人都遇到过这样的情况:数据库的数据文件才2G左右,但是日志文件就已经20G多,如何收缩数据库日志文件呢?
大致的方法有以下几种:
1.DUMP TRANSACTION database_name WITH NO_LOG 清空事务日志
2.BACKUP LOG WITH NO_LOG 截断事务日志
3.BACKUP LOG WITH TRUNCATE_ONLY 截断事务日志
4.DBCC SHRINKDATABASE() 收缩指定数据库中的数据文件和日志文件的大小
5.DBCC SHRINKFILE() 收缩当前数据库的指定数据或日志文件的大小
6.删除日志文件
其中前3中方法是SQL Server 2008 中不再可用的数据库引擎功能,使用了第四种方法感觉效果不明显.下面我们介绍一下如何使用后两种方法收缩数据库日志文件.
1.使用DBCC SHRINKFILE() 收缩当前数据库的指定数据或日志文件的大小,以AdventureWorks数据库为例
USE AdventureWorks;
GO
— 设置AdventureWorks数据库的恢复模式为简单
ALTER DATABASE AdventureWorks
SET RECOVERY SIMPLE;
GO
— 收缩数据库日志文件到1M
DBCC SHRINKFILE (AdventureWorks_Log, 1);
GO
— 设置AdventureWorks数据库的恢复模式为完全
ALTER DATABASE AdventureWorks
SET RECOVERY FULL;
GO
2.删除日志文件,以AdventureWorks数据库为例
USE master
GO
— 分离AdventureWorks数据库
EXEC sp_detach_db ‘AdventureWorks’
GO
— 删除日志文件
EXEC master..xp_cmdshell ‘del “C:/Program Files/Microsoft SQL Server/MSSQL10.MSSQLSERVER/MSSQL/DATA/AdventureWorks_Log.ldf”‘
GO
— 如果cmdshell功能不可使用则使用下面语句激活cmdshell功能
USE master
GO
sp_configure ‘show advanced options’, 1
GO
RECONFIGURE WITH OVERRIDE
GO
sp_configure ‘xp_cmdshell’, 1
RECONFIGURE WITH OVERRIDE
GO
— 使用sp_attach_single_file_db附加.mdf文件
USE master
GO
EXEC sp_attach_single_file_db ‘AdventureWorks’, ‘C:/Program Files/Microsoft SQL Server/MSSQL10.MSSQLSERVER/MSSQL/DATA/AdventureWorks_Data.mdf’
GO
或者
— 使用”CREATE DATABASE database_name FOR ATTACH_REBUILD_LOG”附加数据库(推荐使用)
CREATE DATABASE AdventureWorks ON
(FILENAME = ‘C:/Program Files/Microsoft SQL Server/MSSQL10.MSSQLSERVER/MSSQL/DATA/AdventureWorks_Data.mdf’)
FOR ATTACH_REBUILD_LOG
GO
我将讨论如果一个查询可以被参数化,那么SQL Server优化器怎样尝试将其参数化,以及你可以怎样建立你自己的参数化查询.
1.什么是参数化查询?
一个简单理解参数化查询的方式是把它看做只是一个T-SQL查询,它接受控制这个查询返回什么的参数.通过使用不同的参数,一个参数化查询返回不同的结果.要获得一个参数化查询,你需要以一种特定的方式来编写你的代码,或它需要满足一组特定的标准.
有两种不同的方式来创建参数化查询.第一个方式是让查询优化器自动地参数化你的查询.另一个方式是通过以一个特定方式来编写你的T-SQL代码,并将它传递给sp_executesql系统存储过程,从而编程一个参数化查询.这篇文章的后面部分将介绍这个方法.
参数化查询的关键是查询优化器将创建一个可以重用的缓存计划.通过自动地或编程使用参数化查询,SQL Server可以优化类似T-SQL语句的处理.这个优化消除了对使用高贵资源为这些类似T-SQL语句的每一次执行创建一个缓存计划的需求.而且通过创建一个可重用计划,SQL Server还减少了存放过程缓存中类似的执行计划所需的内存使用.
2.现在让我们看看使得SQL Server创建参数化查询的不同方式.
参数化查询是怎样自动创建的?
微软编写查询优化器代码的人竭尽全力地优化SQL Server处理你的T-SQL命令的方式.我想这是查询优化器名称的由来.这些尽量减少资源和最大限度地提高查询优化器执行性能的方法之一是查看一个T-SQL语句并确定它们是否可以被参数化.要了解这是如何工作的,让我们看看下面的T-SQL语句:
SELECT * FROM AdventureWorks.Sales.SalesOrderHeader
WHERE SalesOrderID = 56000;
GO
在这里,你可以看到这个命令有两个特点.第一它简单,第二它在WHERE谓词中包含一个用于SalesOrderID值的指定值.查询优化器可以识别这个查询比较简单以及SalesOrderID有一个参数(“56000”).因此,查询优化器可以自动地参数化这个查询.
如果你使用下面的SELECT语句来查看一个只包含用于上面语句的缓存计划的,干净的缓冲池,那么你会看到查询优化器将T-SQL查询重写为一个参数化T-SQL语句:
SELECT stats.execution_count AS cnt, p.size_in_bytes AS [size], [sql].[text] AS [plan_text]
FROM sys.dm_exec_cached_plans p
OUTER APPLY sys.dm_exec_sql_text (p.plan_handle) sql
JOIN sys.dm_exec_query_stats stats ON stats.plan_handle = p.plan_handle
GO
当我在一个SQL Server 2008实例上运行这个命令时,我得到下面的输出,(注意,输出被重新格式化了,以便它更易读):

如果你看看上面输出中的plan_text字段,你会看到它不像原来的T-SQL文本.如前所述,查询优化器将这个查询重新编写为一个参数化T-SQL语句.在这里,你可以看到它现在有一个数据类型为(int)的变量(@1),它在之前的SELECT语句中被定义的.另外在plan_text的末尾,值“56000”被替换为变量@1.既然这个T-SQL语句被重写了,而且被存储为一个缓存计划,那么如果未来一个T-SQL命令和它大致相同,只有SalesOrderID字段被赋的值不同的话,它就可以被用于重用.让我们在动作中看看它.
如果我在我的机器上运行下面的命令:
DBCC FREEPROCCACHE
GO
SELECT * FROM AdventureWorks.Sales.SalesOrderHeader
WHERE SalesOrderID = 56000;
GO
SELECT * FROM AdventureWorks.Sales.SalesOrderHeader
WHERE SalesOrderID = 56001;
GO
SELECT stats.execution_count AS cnt, p.size_in_bytes AS [size], [sql].[text] AS [plan_text]
FROM sys.dm_exec_cached_plans p
OUTER APPLY sys.dm_exec_sql_text (p.plan_handle) sql
JOIN sys.dm_exec_query_stats stats ON stats.plan_handle = p.plan_handle
GO
我从最后的SELECT语句得到下面的输出,(注意,输出被重新格式化以便它更易读):

在这里,我首先释放过程缓存,然后我执行两个不同、但却类似的非参数化查询来看看查询优化器是会创建两个不同的缓存计划还是创建用于这两个查询的一个缓存计划.在这里,你可以看到查询优化器事实上很聪明,它参数化第一个查询并缓存了计划.然后当第二个类似、但有一个不同的SalesOrderID值的查询发送到SQL Server时,优化器可以识别已经缓存了一个计划,然后重用它来处理第二个查询.你可以这么说是因为“cnt”字段现在表明这个计划被用了两次.
3.数据库配置选项PARAMETERIZATION可以影响T-SQL语句怎样被自动地参数化.对于这个选项有两种不同的设置,SIMPLE和FORCED.当PARAMETERIZATION设置被设置为SIMPLE时,只有简单的T-SQL语句才会被参数化.要介绍这个,看下下面的命令:
SELECT SUM(LineTotal) AS LineTotal
FROM AdventureWorks.Sales.SalesOrderHeader H
JOIN AdventureWorks.Sales.SalesOrderDetail D ON D.SalesOrderID = H.SalesOrderID
WHERE H.SalesOrderID = 56000
这个查询类似于我前面的示例,除了在这里我添加了一个额外的JOIN标准.当数据库AdventureWorks的PARAMETERIZATION选项被设置为SIMPLE时,这个查询不会被自动地参数化.SIMPLE PARAMETERIZATION设置告诉查询优化器只参数化简单的查询.但是当选项PARAMETERIZATION被设置为FORCED时,这个查询将被自动地参数化.
当你设置数据库选项为使用FORCE PARAMETERIZATION时,查询优化器试图参数化所有的查询,而不仅仅是简单的查询.你可能会认为这很好.但是在某些情况下,当数据库设置PARAMETERIZATION为FORCED时,查询优化器将选择不是很理想的查询计划.当数据库设置PARAMETER为FORCED时,它改变查询中的字面常量.这可能导致当查询中涉及计算字段时索引和索引视图不被选中参与到执行计划中,从而导致一个无效的计划.FORCED PARAMETERIZATION选项可能是改进具有大量类似的、传递过来的参数稍有不同的查询的数据库性能的一个很好的解决方案.一个在线销售应用程序,它的客户对你的产品执行大量的类似搜索, 产品值不同,这可能是一个能够受益于FORCED PARAMETERIZATION的很好的应用程序类型.
不是所有的查询从句都会被参数化.例如查询的TOP、TABLESAMPLE、 HAVING、GROUP BY、ORDER BY、OUTPUT…INTO或FOR XML从句不会被参数化.
4.使用sp_execute_sql来参数化你的T-SQL
你不需要依赖于数据库的PARAMETERIZATION选项来使得查询优化器参数化一个查询.你可以参数化你自己的查询.你通过重新编写你的T-SQL语句并使用”sp_executesql”系统存储过程执行重写的语句来实现.正如已经看到的,上面包括一个“JOIN”从句的SELECT语句在数据库的PARAMETERIZATION设置为SIMPLE时没有被自动参数化.让我重新编写这个查询以便查询优化器将创建一个可重用的参数化查询执行计划.
为了说明,让我们看两个类似的、不会被自动参数化的T-SQL语句,并创建两个不同的缓存执行计划.然后我将重新编写这两个查询使得它们都使用相同的缓存参数化执行计划.
让我们看看这个代码:
DBCC FREEPROCCACHE
GO
SELECT SUM(LineTotal) AS LineTotal
FROM AdventureWorks.Sales.SalesOrderHeader H
JOIN AdventureWorks.Sales.SalesOrderDetail D ON D.SalesOrderID = H.SalesOrderID
WHERE H.SalesOrderID = 56000
GO
SELECT SUM(LineTotal) AS LineTotal
FROM AdventureWorks.Sales.SalesOrderHeader H
JOIN AdventureWorks.Sales.SalesOrderDetail D ON D.SalesOrderID = H.SalesOrderID
WHERE H.SalesOrderID = 56001
GO
SELECT stats.execution_count AS cnt, p.size_in_bytes AS [size], [sql].[text] AS [plan_text]
FROM sys.dm_exec_cached_plans p
OUTER APPLY sys.dm_exec_sql_text (p.plan_handle) sql
JOIN sys.dm_exec_query_stats stats ON stats.plan_handle = p.plan_handle
GO
在这里,我释放了过程缓存,然后运行这两个包含一个JOIN的、不同的非简单的T-SQL语句.然后我将检查缓存计划.这是这个使用DMV 的SELECT语句的输出(注意,输出被重新格式化了,以便它更易读):

正如你从这个输出看到的,这两个SELECT语句没有被查询优化器参数化.优化器创建了两个不同的缓存执行计划,每一个都只被执行了一次.我们可以通过使用sp_executesql系统存储过程来帮助优化器为这两个不同的SELECT语句创建一个参数化执行计划.
下面是上面的代码被重新编写来使用sp_executesql 系统存储过程:
DBCC FREEPROCCACHE
GO
EXEC sp_executesql N’SELECT SUM(LineTotal) AS LineTotal
FROM AdventureWorks.Sales.SalesOrderHeader H
JOIN AdventureWorks.Sales.SalesOrderDetail D ON D.SalesOrderID = H.SalesOrderID
WHERE H.SalesOrderID = @SalesOrderID’, N’@SalesOrderID INT’, @SalesOrderID = 56000
GO
EXEC sp_executesql N’SELECT SUM(LineTotal) AS LineTotal
FROM AdventureWorks.Sales.SalesOrderHeader H
JOIN AdventureWorks.Sales.SalesOrderDetail D ON D.SalesOrderID = H.SalesOrderID
WHERE H.SalesOrderID = @SalesOrderID’, N’@SalesOrderID INT’, @SalesOrderID = 56001
GO
SELECT stats.execution_count AS cnt, p.size_in_bytes AS [size], [sql].[text] AS [plan_text]
FROM sys.dm_exec_cached_plans p
OUTER APPLY sys.dm_exec_sql_text (p.plan_handle) sql
JOIN sys.dm_exec_query_stats stats ON stats.plan_handle = p.plan_handle
GO
如同你所看到的,我重新编写了这两个SELECT语句,使它们通过使用”EXEC sp_executesql”语句来执行.对这些EXEC语句中的每一个,我都传递三个不同的参数.第一个参数是基本的SELECT语句,但是我将SalesOrderID的值用一个变量(@SalesOrderID)替代.在第二个参数中,我确定了@SalesOrderID的数据类型,在这个例子中它是一个integer.然后在最后一个参数中,我传递了SalesOrderID的值.这个参数将控制我的SELECT根据SalesOrderID值所生成的结果.sp_executesql的每次执行中前两个参数都是一样的.但是第三个参数不同,因为每个都有不同的SalesOrderID值.
现在当我运行上面的代码时,我从DMV SELECT语句得到下面的输出(注意,输出被重新格式化了,以便它更易读):

从这个输出,你可以看出,我有一个参数化缓存计划,它被执行了两次,为每个EXEC语句各执行了一次.
使用参数化查询来节省资源和优化性能
在语句可以被执行之前,每个T-SQL语句都需要被评估,而且需要建立一个执行计划.创建执行计划会占用宝贵的CPU资源.当执行计划被创建后,它使用内存空间将它存储在过程缓存中.降低CPU和内存使用的一个方法是利用参数化查询.尽管数据库可以被设置为对所有查询FORCE参数化,但是这不总是最好的选择.通过了解你的哪些T-SQL语句可以被参数化然后使用sp_executesql存储过程,你可以帮助SQL Server节省资源并优化你的查询的性能.
Transact-SQL 编程语言提供 DBCC 语句作为 SQL Server 的数据库控制台命令
数据库控制台命令语句可分为以下类别
|
命令类别 |
执行 |
|
维护 |
对数据库、索引或文件组进行维护的任务 |
|
杂项 |
杂项任务,如启用跟踪标志或从内存中删除 DLL |
|
信息 |
收集并显示各种类型信息的任务 |
|
验证 |
对数据库、表、索引、目录、文件组或数据库页的分配进行的验证操作 |
— I.信息语句
— 1.DBCC INPUTBUFFER 根据session_id显示从客户端发送到 Microsoft SQL Server 实例的一个语句
SELECT @@SPID — 获得当前会话ID
SELECT * FROM sys.dm_exec_requests WHERE session_id = @@spid — 跟据当前会话ID获得此次请求信息
DBCC INPUTBUFFER(@@SPID) WITH NO_INFOMSGS — 显示从客户端发送到 Microsoft SQL Server 实例的一个语句
— 2.DBCC SHOWCONTIG 显示指定的表或视图的数据和索引的碎片信息,建议使用 sys.dm_db_index_physical_stats
USE AdventureWorks
GO
DBCC SHOWCONTIG (‘Person.Address’) WITH NO_INFOMSGS — 显示Person.Address表的数据和索引的碎片信息
GO
— 返回所有数据库中所有对象的信息
SELECT * FROM sys.dm_db_index_physical_stats (NULL, NULL, NULL, NULL, NULL);
— 返回AdventureWorks数据库中Person.Address表的信息
SELECT * FROM sys.dm_db_index_physical_stats
(DB_ID(N’AdventureWorks’), OBJECT_ID(N’Person.Address’), NULL, NULL , ‘DETAILED’);
GO
— 3.DBCC OPENTRAN 确定打开的事务是否存在于事务日志中
DBCC OPENTRAN (0) — 当前数据库
DBCC OPENTRAN (N’AdventureWorks’) — AdventureWorks数据库
— 创建数据库和表并打开一个事务
USE master
GO
CREATE DATABASE Test
GO
USE Test
GO
CREATE TABLE T1
(col1 INT,
col2 VARCHAR(10))
GO
BEGIN TRAN
INSERT INTO T1 VALUES (1, ‘Kobe’);
GO
DBCC OPENTRAN; — 查看此数据库中打开的事务
ROLLBACK TRAN;
GO
DROP TABLE T1;
GO
USE master
GO
DROP DATABASE Test
GO
— 4.DBCC SQLPERF 提供所有数据库的事务日志空间使用情况统计信息,也可以用于重置等待和闩锁的统计信息.
DBCC SQLPERF(LOGSPACE) WITH NO_INFOMSGS; — 显示所有数据库的日志空间信息
GO
DBCC SQLPERF(“sys.dm_os_latch_stats”,CLEAR) WITH NO_INFOMSGS; — SQL Server 实例重置闩锁统计信息
GO
DBCC SQLPERF(“sys.dm_os_wait_stats”,CLEAR) WITH NO_INFOMSGS; — SQL Server 实例重置等待统计信息
GO
SELECT * FROM sys.dm_os_latch_stats — 返回按类组织的所有闩锁等待的相关信息
GO
SELECT * FROM sys.dm_os_wait_stats — 返回执行的线程所遇到的所有等待的相关信息
GO
— 5.DBCC OUTPUTBUFFER 以十六进制和 ASCII 格式返回指定 session_id 的当前输出缓冲区
SELECT @@SPID
DBCC OUTPUTBUFFER (@@SPID) WITH NO_INFOMSGS — 返回当前进程缓冲区内容
— 6.DBCC TRACESTATUS 显示跟踪标志的状态
— 在 SQL Server 中,有两种跟踪标志:会话和全局.会话跟踪标志对某个连接是有效的,只对该连接可见;
— 全局跟踪标志在服务器级别上进行设置,对服务器上的每一个连接都可见.
DBCC TRACESTATUS(-1) WITH NO_INFOMSGS; — 显示当前全局启用的所有跟踪标志的状态
GO
DBCC TRACESTATUS (2528, 3205) WITH NO_INFOMSGS; — 显示跟踪标志 2528 和 3205 的状态
GO
DBCC TRACESTATUS (3205, -1) WITH NO_INFOMSGS; — 以下示例显示跟踪标志 3205 是否是全局启用的
GO
DBCC TRACESTATUS() WITH NO_INFOMSGS; — 列出针对当前会话启用的所有跟踪标志
GO
— 7.DBCC PROCCACHE 以表格格式显示有关过程缓存的信息
— 使用过程缓存来缓存已编译计划和可执行计划,以加快批处理的执行速度.过程缓存中的项处于批处理级别.过程缓存包括以下项:
— A.已编译计划;B.执行计划;C.Algebrizer 树;D.扩展过程
DBCC PROCCACHE WITH NO_INFOMSGS
— 8.DBCC USEROPTIONS 返回当前连接的活动(设置)的 SET 选项
DBCC USEROPTIONS WITH NO_INFOMSGS;
GO
— 9.DBCC SHOW_STATISTICS 显示索引,统计信息或列的当前查询优化统计信息.根据统计信息对象中存储的数据,显示的相应统计信息包括标题,直方图和密度
USE AdventureWorks;
GO
— 以下示例显示 Person.Address 表的 AK_Product_Name 索引的所有统计信息
DBCC SHOW_STATISTICS (“Person.Address”, AK_Address_rowguid) — WITH NO_INFOMSGS, STAT_HEADER, DENSITY_VECTOR, HISTOGRAM;
GO
DBCC SHOW_STATISTICS (“Person.Address”, PK_Address_AddressID)
GO
— II.验证语句
— 1.DBCC CHECKALLOC 检查指定数据库的磁盘空间分配结构的一致性
DBCC CHECKALLOC; — 不指定此参数或指定了 0 值,则默认值为当前数据库
GO
DBCC CHECKALLOC (N’AdventureWorks’); — 检查AdventureWorks数据库
GO
— 显示当指定所有其他选项时运行 DBCC CHECKALLOC 所需的估计 tempdb 空间大小
DBCC CHECKALLOC WITH ALL_ERRORMSGS, NO_INFOMSGS, TABLOCK, ESTIMATEONLY
GO
— 2.DBCC CHECKFILEGROUP 检查当前数据库中指定文件组中的所有表和索引视图的分配和结构完整性
USE AdventureWorks;
GO
— 不指定此参数或指定了 0 值,则默认值为主文件组
DBCC CHECKFILEGROUP;
GO
— 通过指定主文件组的标识号并指定 NOINDEX,对 AdventureWorks 数据库主文件组(不包括非聚集索引)进行检查
DBCC CHECKFILEGROUP (1, NOINDEX);
GO
— 检查 AdventureWorks 数据库主文件组并指定选项 ESTIMATEONLY,所需的估计 tempdb 空间大小
DBCC CHECKFILEGROUP (1) WITH ESTIMATEONLY;
GO
— 3.DBCC CHECKCATALOG 检查指定数据库内的目录一致性.数据库必须联机
DBCC CHECKCATALOG; — Check the current database.
GO
DBCC CHECKCATALOG (AdventureWorks); — Check the AdventureWorks database.
GO
— 4.DBCC CHECKIDENT 检查指定表的当前标识值,如有必要,则更改标识值.还可以使用 DBCC CHECKIDENT 为标识列手动设置新的当前标识值
USE AdventureWorks;
GO
DBCC CHECKIDENT (“HumanResources.Employee”); — 据需要重置 AdventureWorks 数据库中 Employee 表的当前标识值
GO
DBCC CHECKIDENT (“HumanResources.Employee”, NORESEED);– 报告 AdventureWorks 数据库的 Employee 表中的当前标识值,但如果该标识值不正确,不会进行更正
GO
DBCC CHECKIDENT (“HumanResources.Employee”, RESEED, 30);– 将 AdventureWorks 数据库的 Employee 表中的当前标识值强制设置为值 30
GO
— 5.DBCC CHECKCONSTRAINTS 检查当前数据库中指定表上的指定约束或所有约束的完整性
— 例检查 AdventureWorks 数据库中的 Table1 表的约束完整性
USE AdventureWorks;
GO
CREATE TABLE Table1 (Col1 int, Col2 char (30));
GO
INSERT INTO Table1 VALUES (100, ‘Hello’);
GO
ALTER TABLE Table1 WITH NOCHECK ADD CONSTRAINT chkTab1 CHECK (Col1 > 100);
GO
DBCC CHECKCONSTRAINTS(Table1);
GO
DROP TABLE Table1
GO
DBCC CHECKCONSTRAINTS (“Production.CK_ProductCostHistory_EndDate”);– 检查 CK_ProductCostHistory_EndDate 约束的完整性
GO
DBCC CHECKCONSTRAINTS WITH ALL_CONSTRAINTS; — 检查当前数据库中所有表上的所有启用和禁用约束的完整性
GO
— 6.DBCC CHECKTABLE 检查组成表或索引视图的所有页和结构的完整性
— 若要对数据库中的每个表执行 DBCC CHECKTABLE,请使用 DBCC CHECKDB-
— 对于指定的表,DBCC CHECKTABLE 将检查以下内容:
— A.是否已正确链接索引,行内,LOB 以及行溢出数据页;
— B.索引是否按照正确的顺序排列;
— C.各指针是否一致;
— D.每页上的数据是否合理(包括计算列);
— E.页面偏移量是否合理;
— F.基表的每一行是否在每个非聚集索引中具有匹配的行,以及非聚集索引的每一行是否在基表中具有匹配的行;
— G.已分区表或索引的每一行是否都位于正确的分区中;
— H.使用 FILESTREAM 将 varbinary(max) 数据存储在文件系统中时,文件系统与表之间是否保持链接级一致性;
USE AdventureWorks;
GO
DBCC CHECKTABLE (“HumanResources.Employee”);– 检查 AdventureWorks 数据库中的 HumanResources.Employee 表的数据页完整性
GO
DBCC CHECKTABLE (“HumanResources.Employee”) WITH PHYSICAL_ONLY;– 将以较低的开销检查 AdventureWorks 数据库中的 Employee 表
GO
DECLARE @indid int;
SET @indid = (SELECT index_id
FROM sys.indexes
WHERE object_id = OBJECT_ID(‘Production.Product’)
AND name = ‘AK_Product_Name’);
DBCC CHECKTABLE (“Production.Product”, @indid); — 将检查通过访问 sys.indexes 获得的特定索引
— 7.DBCC CHECKDB
— 通过执行下列操作检查指定数据库中所有对象的逻辑和物理完整性:
— A.对数据库运行 DBCC CHECKALLOC;
— B.对数据库中的每个表和视图运行 DBCC CHECKTABLE;
— C.对数据库运行 DBCC CHECKCATALOG;
— D.验证数据库中每个索引视图的内容;
— E.使用 FILESTREAM 在文件系统中存储 varbinary(max) 数据时,验证表元数据和文件系统目录和文件之间的链接级一致性;
— F.验证数据库中的 Service Broker 数据;
— 这意味着不必从 DBCC CHECKDB 单独运行 DBCC CHECKALLOC,DBCC CHECKTABLE 或 DBCC CHECKCATALOG 命令
— Check the current database.
DBCC CHECKDB;
GO
— Check the AdventureWorks database without nonclustered indexes.
DBCC CHECKDB (AdventureWorks, NOINDEX);
GO
DBCC CHECKDB WITH NO_INFOMSGS; — 检查当前数据库,取消信息性消息
GO
— III.维护语句
— 1.DBCC CLEANTABLE 回收表或索引视图中已删除的可变长度列的空间
— DBCC CLEANTABLE 用于在删除可变长度列之后回收空间,可变长度列可以属于下列数据类型之一:varchar,nvarchar,varchar(max),nvarchar(max),varbinary,varbinary(max),text,ntext,image,sql_variant 和 xml.该命令不回收删除固定长度列后的空间.
— 如果删除的列存储在行内,则 DBCC CLEANTABLE 将从表的 IN_ROW_DATA 分配单元回收空间;如果列存储在行外,则将根据已删除列的数据类型从 ROW_OVERFLOW_DATA 或 LOB_DATA 分配单元回收空间;如果从 ROW_OVERFLOW_DATA 或 LOB_DATA 页回收空间时产生空页,DBCC CLEANTABLE 将删除该页
— DBCC CLEANTABLE 作为一个或多个事务运行。如果未指定批大小,则该命令将在一个事务中处理整个表,并在操作过程中以独占方式锁定该表.对于某些大型表,单个事务的长度和所需的日志空间可能太大.如果指定批大小,则该命令将在一系列事务中运行,每个事务包括指定的行数.DBCC CLEANTABLE 不能作为其他事务内的事务运行
— 该操作将被完整地记入日志。
— 系统表或临时表不支持使用 DBCC CLEANTABLE。
— 不应将 DBCC CLEANTABLE 作为日常维护任务来执行.而应在对表或索引视图中的可变长度列进行重要更改之后并且需要立即回收未使用空间时使用 DBCC CLEANTABLE.或者,也可以重新生成表或视图的索引;但是,此操作会耗费更多资源
DBCC CLEANTABLE (AdventureWorks,”Person.Address”, 0) WITH NO_INFOMSGS;
GO
— 创建一个表并用几个可变长度列填充该表.然后删除其中两列,并运行 DBCC CLEANTABLE 以回收未使用空间.在执行 DBCC CLEANTABLE 命令之前和之后,运行查询以验证页计数和已用空间值
USE AdventureWorks;
GO
IF OBJECT_ID (‘dbo.CleanTableTest’, ‘U’) IS NOT NULL
DROP TABLE dbo.CleanTableTest;
GO
— 创建测试表 CleanTableTest
CREATE TABLE dbo.CleanTableTest
(DocumentID int Not Null,
FileName nvarchar(4000),
DocumentSummary nvarchar(max),
Document varbinary(max)
);
GO
— Populate the table with data from the Production.Document table.
INSERT INTO dbo.CleanTableTest
SELECT DocumentID,
REPLICATE(FileName, 1000), — 返回多次复制后的字符表达式
DocumentSummary,
Document
FROM Production.Document;
GO
— Verify the current page counts and average space used in the dbo.CleanTableTest table.
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N’AdventureWorks’);
SET @object_id = OBJECT_ID(N’AdventureWorks.dbo.CleanTableTest’);
SELECT alloc_unit_type_desc,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , ‘Detailed’);
GO
— Drop two variable-length columns from the table.
ALTER TABLE dbo.CleanTableTest
DROP COLUMN FileName, Document;
GO
— Verify the page counts and average space used in the dbo.CleanTableTest table
— Notice that the values have not changed.
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N’AdventureWorks’);
SET @object_id = OBJECT_ID(N’AdventureWorks.dbo.CleanTableTest’);
SELECT alloc_unit_type_desc,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , ‘Detailed’);
GO
— Run DBCC CLEANTABLE.
DBCC CLEANTABLE (AdventureWorks,”dbo.CleanTableTest”);
GO
— Verify the values in the dbo.CleanTableTest table after the DBCC CLEANTABLE command.
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N’AdventureWorks’);
SET @object_id = OBJECT_ID(N’AdventureWorks.dbo.CleanTableTest’);
SELECT alloc_unit_type_desc,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , ‘Detailed’);
GO
— 2.DBCC INDEXDEFRAG 指定表或视图的索引碎片整理.下一版本的 Microsoft SQL Server 将删除该功能.建议使用 ALTER INDEX
— DBCC INDEXDEFRAG 对索引的叶级进行碎片整理,以便页的物理顺序与叶节点从左到右的逻辑顺序相匹配,因此可提高索引扫描性能
— 对 AdventureWorks 数据库的 Production.Product 表中的 PK_Product_ProductID 索引的所有分区进行碎片整理。
DBCC INDEXDEFRAG (AdventureWorks, “Production.Product”, PK_Product_ProductID)
GO
— 使用 DBCC SHOWCONTIG 和 DBCC INDEXDEFRAG 对数据库中的索引进行碎片整理
— 该方法可用于对数据库中碎片数量在声明的阈值之上的所有索引进行碎片整理
— Declare variables
SET NOCOUNT ON;
DECLARE @tablename varchar(255);
DECLARE @execstr varchar(400);
DECLARE @objectid int;
DECLARE @indexid int;
DECLARE @frag decimal;
DECLARE @maxfrag decimal;
— Decide on the maximum fragmentation to allow for.
SELECT @maxfrag = 30.0;
— Declare a cursor.
DECLARE tables CURSOR FOR
SELECT TABLE_SCHEMA + ‘.’ + TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = ‘BASE TABLE’;
— Create the table.
CREATE TABLE #fraglist (
ObjectName char(255),
ObjectId int,
IndexName char(255),
IndexId int,
Lvl int,
CountPages int,
CountRows int,
MinRecSize int,
MaxRecSize int,
AvgRecSize int,
ForRecCount int,
Extents int,
ExtentSwitches int,
AvgFreeBytes int,
AvgPageDensity int,
ScanDensity decimal,
BestCount int,
ActualCount int,
LogicalFrag decimal,
ExtentFrag decimal);
— Open the cursor.
OPEN tables;
— Loop through all the tables in the database.
FETCH NEXT
FROM tables
INTO @tablename;
WHILE @@FETCH_STATUS = 0
BEGIN;
— Do the showcontig of all indexes of the table
INSERT INTO #fraglist
EXEC (‘DBCC SHOWCONTIG (”’ + @tablename + ”’)
WITH FAST, TABLERESULTS, ALL_INDEXES, NO_INFOMSGS’);
FETCH NEXT
FROM tables
INTO @tablename;
END;
— Close and deallocate the cursor.
CLOSE tables;
DEALLOCATE tables;
— Declare the cursor for the list of indexes to be defragged.
DECLARE indexes CURSOR FOR
SELECT ObjectName, ObjectId, IndexId, LogicalFrag
FROM #fraglist
WHERE LogicalFrag >= @maxfrag
AND INDEXPROPERTY (ObjectId, IndexName, ‘IndexDepth’) > 0;
— Open the cursor.
OPEN indexes;
— Loop through the indexes.
FETCH NEXT
FROM indexes
INTO @tablename, @objectid, @indexid, @frag;
WHILE @@FETCH_STATUS = 0
BEGIN;
PRINT ‘Executing DBCC INDEXDEFRAG (0, ‘ + RTRIM(@tablename) + ‘,
‘ + RTRIM(@indexid) + ‘) – fragmentation currently ‘
+ RTRIM(CONVERT(varchar(15),@frag)) + ‘%’;
SELECT @execstr = ‘DBCC INDEXDEFRAG (0, ‘ + RTRIM(@objectid) + ‘,
‘ + RTRIM(@indexid) + ‘)’;
EXEC (@execstr);
FETCH NEXT
FROM indexes
INTO @tablename, @objectid, @indexid, @frag;
END;
— Close and deallocate the cursor.
CLOSE indexes;
DEALLOCATE indexes;
— Delete the temporary table.
DROP TABLE #fraglist;
GO
— ALTER INDEX index_name ON talbe_name REORGANIZE;
USE AdventureWorks;
GO
ALTER INDEX PK_ProductPhoto_ProductPhotoID ON Production.ProductPhoto REORGANIZE; `– 重新组织单个聚集索引
GO
— 3.DBCC DBREINDEX 对指定数据库中的表重新生成一个或多个索引,下一版本的 Microsoft SQL Server 将删除该功能.建议使用 ALTER INDEX。
— DBCC DBREINDEX 重新生成表的一个索引或为表定义的所有索引.通过允许动态重新生成索引,可以重新生成强制 PRIMARY KEY 或 UNIQUE 约束的索引,而不必删除并重新创建这些约束.这意味着无需了解表的结构或其约束,即可重新生成索引.这可能在将数据大容量复制到表中以后发生
USE AdventureWorks;
GO
— 使用填充因子 80 对 AdventureWorks 数据库中的 Employee 表重新生成 Employee_EmployeeID 聚集索引
DBCC DBREINDEX (“HumanResources.Employee”, PK_Employee_EmployeeID,80);
GO
— ALTER INDEX index_name ON talbe_name REBUILD;
USE AdventureWorks;
GO
ALTER INDEX PK_Employee_EmployeeID ON HumanResources.Employee REBUILD; — 在 Employee 表中重新生成单个索引
GO
— 4.DBCC SHRINKDATABASE 收缩指定数据库中的数据文件和日志文件的大小
— 若要收缩特定数据库的所有数据和日志文件,请执行 DBCC SHRINKDATABASE 命令;若要一次收缩一个特定数据库中的一个数据或日志文件,请执行 DBCC SHRINKFILE 命令
— 若要查看数据库中当前的可用(未分配)空间量,请运行 sp_spaceused
EXEC sp_spaceused
DBCC SHRINKDATABASE (AdventureWorks, 10);
GO
— 5.DBCC DROPCLEANBUFFERS 从缓冲池中删除所有清除缓冲区
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS
— 6.DBCC SHRINKFILE 收缩当前数据库的指定数据或日志文件的大小,或通过将数据从指定的文件移动到相同文件组中的其他文件来清空文件,以允许从数据库中删除该文件.文件大小可以收缩到比创建该文件时所指定的大小更小.这样会将最小文件大小重置为新值
— 将日志文件收缩到指定的目标大小,将 AdventureWorks 数据库中的日志文件收缩到 1 MB.若要允许 DBCC SHRINKFILE 命令收缩文件,首先需要通过将数据库恢复模式设置为 SIMPLE 来截断该文件.
— 将 AdventureWorks 用户数据库中名为 DataFile1 的数据文件的大小收缩到 1 MB。
USE AdventureWorks;
GO
DBCC SHRINKFILE (DataFile1, 1);
GO
USE AdventureWorks;
GO
— Truncate the log by changing the database recovery model to SIMPLE.
ALTER DATABASE AdventureWorks
SET RECOVERY SIMPLE;
GO
— Shrink the truncated log file to 1 MB.
DBCC SHRINKFILE (AdventureWorks_Log, 1);
GO
— Reset the database recovery model.
ALTER DATABASE AdventureWorks
SET RECOVERY FULL;
GO
— 清空文件以便从数据库中将其删除的步骤
USE AdventureWorks;
GO
— Create a data file and assume it contains data.
ALTER DATABASE AdventureWorks
ADD FILE (
NAME = Test1data,
FILENAME = ‘C:/t1data.ndf’,
SIZE = 5MB
);
GO
— Empty the data file.
DBCC SHRINKFILE (Test1data, EMPTYFILE);
GO
— Remove the data file from the database.
ALTER DATABASE AdventureWorks
REMOVE FILE Test1data;
GO
— 7.DBCC FREEPROCCACHE 删除计划缓存中的所有元素,通过指定计划句柄或 SQL 句柄从计划缓存删除特定计划,或者删除指定资源池中的所有工作负荷组
— 通过指定查询计划句柄从计划缓存中清除查询计划.为了确保示例查询在计划缓存中,首先执行该查询.将查询 sys.dm_exec_cached_plans 和 sys.dm_exec_sql_text 动态管理视图以返回查询的计划句柄.然后,将结果集中的计划句柄值插入 DBCC FREEPROCACHE 语句,以从计划缓存中仅删除该计划
USE AdventureWorks;
GO
SELECT * FROM Person.Address;
GO
SELECT plan_handle, st.text
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS st
WHERE text LIKE N’SELECT * FROM Person.Address%’;
GO
— Remove the specific plan from the cache.
DBCC FREEPROCCACHE (0x060006001ECA270EC0215D05000000000000000000000000);
GO
— 清除计划缓存中的所有计划
— 小心使用 DBCC FREEPROCCACHE 清除计划缓存.释放计划缓存将导致系统重新编译存储过程,而不重用缓存中的存储过程.这会导致查询性能暂时性地突然降低.对于计划缓存中每个已清除的缓存存储区
DBCC FREEPROCCACHE WITH NO_INFOMSGS;
— 8.DBCC UPDATEUSAGE 报告目录视图中的页数和行数错误并进行更正
DBCC UPDATEUSAGE (0); — 为当前数据库中的所有对象更新页数或行数,或同时更新两者
GO
USE AdventureWorks;
GO
DBCC UPDATEUSAGE (AdventureWorks) WITH NO_INFOMSGS; — 为 AdventureWorks 更新页数和行数,或同时更新两者,并禁止显示信息性消息
GO
DBCC UPDATEUSAGE (AdventureWorks,”HumanResources.Employee”);– 报告 AdventureWorks 数据库中 Employee 表的已更新页数或行数信息
GO
DBCC UPDATEUSAGE (AdventureWorks, “HumanResources.Employee”, IX_Employee_ManagerID);– 为表中的特定索引更新页数或行数,或同时更新两者
GO
— IV.杂项语句
— 1.DBCC dllname (FREE) 从内存中释放指定的扩展存储过程 DLL
— 执行扩展存储过程时,DLL 仍保持由 SQL Server 的实例加载,直到服务器关闭为止.此语句允许从内存中卸载 DLL,而不用关闭 SQL Server
DBCC xpstar ( FREE ) WITH NO_INFOMSGS
— 存储过程 sp_helpextendedproc 报告当前定义的扩展存储过程以及该过程(函数)所属的动态链接库(DLL)的名称,后续版本的 Microsoft SQL Server 将删除该功能
USE master;
GO
EXEC sp_helpextendedproc; — 对所有扩展存储过程进行报告
GO
EXEC sp_helpextendedproc xp_cmdshell; — 对 xp_cmdshell 扩展存储过程进行报告
GO
— 2.DBCC TRACEOFF 禁用指定的跟踪标记
DBCC TRACEOFF (3205) WITH NO_INFOMSGS; — 禁用跟踪标记 3205
GO
DBCC TRACEOFF (3205, -1) WITH NO_INFOMSGS; — 全局禁用跟踪标记 3205
GO
DBCC TRACEOFF (3205, 260, -1) WITH NO_INFOMSGS; — 全局禁用跟踪标记 3205 和 260
GO
— 3.DBCC TRACEON 启用指定的跟踪标记
— 在生产服务器上,为了避免意外行为,建议您使用下列方法之一,仅在服务器范围内启用跟踪标记:
— A.使用 Sqlservr.exe 的 -T 命令行启动选项.这是推荐的最佳实践,因为这样可确保将所有语句运行时使用已启用的跟踪标志.这些语句包括启动脚本中的命令
— B.仅在用户或应用程序未对系统以并行方式运行语句时,才使用 DBCC TRACEON ( trace# [, ….n], -1 )
— 跟踪标记用于通过控制 SQL Server 的运行方式来自定义某些特征.启用的跟踪标记将在服务器中一直保持启用状态,
— 直到执行 DBCC TRACEOFF 语句将其禁用为止.在 SQL Server 中,有两种跟踪标志:会话和全局.会话跟踪标志对某个连接是有效的,只对该连接可见;
— 全局跟踪标志在服务器级别上进行设置,对服务器上的每一个连接都可见.若要确定跟踪标记的状态,请使用 DBCC TRACESTATUS.若要禁用跟踪标记,请使用 DBCC TRACEOFF
DBCC TRACEON (3205) WITH NO_INFOMSGS; — 打开跟踪标记 3205,禁用磁带驱动程序的硬件压缩功能.仅为当前连接打开此标记
GO
DBCC TRACEON (3205, -1) WITH NO_INFOMSGS; — 全局方式打开跟踪标记 3205
GO
DBCC TRACEON (3205, 260, -1) WITH NO_INFOMSGS; — 全局方式打开跟踪标记 3205 和 260
GO
— 4.DBCC HELP 返回指定的 DBCC 命令的语法信息
DBCC HELP (‘?’); — 返回可查看其帮助信息的所有 DBCC 语句
GO
DBCC HELP (‘checkdb’); — 返回 DBCC CHECKDB 的语法信息
GO
— V.其它语句
— 1.DBCC FREESESSIONCACHE 刷新针对 Microsoft SQL Server 实例执行的分布式查询所使用的分布式查询连接缓存
USE AdventureWorks;
GO
DBCC FREESESSIONCACHE WITH NO_INFOMSGS; — 将刷新分布式查询缓存
GO
— 2.DBCC FREESYSTEMCACHE 从所有缓存中释放所有未使用的缓存条目.
— SQL Server 数据库引擎会事先在后台清理未使用的缓存条目,以使内存可用于当前条目.但是,可以使用此命令从所有缓存中手动删除未使用的条目
— Clean all the caches with entries specific to the resource pool named “default”.
DBCC FREESYSTEMCACHE (‘ALL’,’default’) — 清除特定于某个资源调控器资源池的缓存
— 3.DBCC PINTABLE 将表标记为驻留,这表示 Microsoft SQL Server 不从内存中刷新表页
— DBCC PINTABLE 不会导致将表读入到内存中.当表中的页由普通的 Transact-SQL 语句读入到高速缓存中时,这些页将标记为内存驻留页.
— 当 SQL Server 需要空间以读入新页时,不会清空内存驻留页.SQL Server 仍然记录对页的更新,并且如有必要,将更新的页写回到磁盘.
— 然而,在使用 DBCC UNPINTABLE 语句使该表不驻留之前,SQL Server 在高速缓存中一直保存可用页的复本.
— DBCC PINTABLE 最适用于将小的,经常引用的表保存在内存中.将小表的页一次性读入到内存中,将来对其数据的所有引用都不需要从磁盘读入.
— 驻留 AdventureWorks 数据库中的 Person.Address 表
DECLARE @db_id int, @tbl_id int
USE AdventureWorks
SET @db_id = DB_ID(‘AdventureWorks’)
SET @tbl_id = OBJECT_ID(‘Person.Address’)
DBCC PINTABLE (@db_id, @tbl_id)
GO
— 4.DBCC UNPINTABLE 将表标记为不在内存驻留.将表标记为不在内存驻留后,可以清空高速缓存中的表页
— DBCC UNPINTABLE 不会导致立即将表从数据高速缓存中清空.而指定如果需要空间以从磁盘中读入新页,高速缓存中的表的所有页都可以清空
— 不驻留 AdventureWorks 数据库中的 Person.Address 表
DECLARE @db_id int, @tbl_id int
USE AdventureWorks
SET @db_id = DB_ID(‘AdventureWorks’)
SET @tbl_id = OBJECT_ID(‘Person.Address’)
DBCC UNPINTABLE (@db_id, @tbl_id)
GO
与SQL SERVER 2008 CDC 异步捕获数据变更的不同,更改跟踪是同步进程,是DML(INSERT/UPDATE/DELETE)事务的一部分,它可以使用最小的C盘存储开销来侦测数据行的净变更.那么它也就不能像CDC那样可以提供用户表的历史更改信息.更改是使用异步进程捕获的,此进程读取事务日志,并且对系统造成的影响很小.
更改跟踪捕获更改了表行这一事实,但不会捕获更改的数据.这样,应用程序就可以确定使用从用户表中直接获取的最新行数据更改的行.因此,与变更数据捕获相比,更改跟踪可以解答的历史问题比较有限.但是,对于不需要历史信息的那些应用程序,更改跟踪产生的存储开销要小得多,因为它不需要捕获更改的数据(不需要触发器和表时间戳).它使用同步跟踪机制来跟踪更改.此功能旨在最大限度地减少DML 操作开销.
总的来说有以下几点:
1.减少了开发时间:由于SQL Server 2008 中提供了更改跟踪功能,因此无需开发自定义解决方案.
2.不需要架构更改:使用更改跟踪不需要执行以下任务:添加列;添加触发器;如果无法将列添加到用户表,则需要创建要在其中跟踪已删除的行或存储更改跟踪信息的端表.o
3.内置清除机制:更改跟踪的清除操作在后台自动执行.不需要端表中存储的数据的自定义清除.
4.提供更改跟踪功能的目的是获取更改信息:使用更改跟踪功能可使信息查询和使用更方便.列跟踪记录提供与更改的数据相关的详细信息.
5.降低了DML 操作的开销:同步更改跟踪始终会有一些开销.但是,使用更改跟踪有助于使开销最小化.开销通常会低于使用其他解决方案,对于需要使用触发器的解决方案,尤其如此.
6.更改跟踪是基于提交的事务进行的:更改的顺序基于事务提交时间.在存在长时间运行和重叠事务的情况下,这样可获得可靠的结果.必须专门设计使用timestamp
值的自定义解决方案,以处理这些情况.
7.配置和管理更改跟踪的标准工具:SQL Server 2008 提供标准的DDL 语句、SQL Server Management Studio,目录视图和安全权限.
具体步骤:
1.建立测试数据库
IF NOT EXISTS (SELECT name FROM SYS.databases WHERE name = N’CHANGE_TRACK_DB’)
BEGIN
CREATE DATABASE CHANGE_TRACK_DB
END
要启用数据库更改跟踪功能,需要配置CHANGE_TRACKING数据库选项.也可以配置跟踪的数据在数据库保留多久,以及是否启用自动清除.配置保留期将会影响到需要维护的跟踪数据的大小.该值过高可能会影响存储.太低的话在远程应用程序同步不够的情况下,会引发通另一应用程序的同步问题.
2.配置更改跟踪
ALTER DATABASE CHANGE_TRACK_DB
SET CHANGE_TRACKING = ON(CHANGE_RETENTION = 36HOURS, AUTO_CLEANUP = ON)
使用更改跟踪时的最佳实践是为数据库启用快照隔离.不使用快照隔离会引发事务不一致的变更信息.对有显著DML活动的数据库和表,以一致的方式捕获更改跟踪的信息很重要(抓取最新版本并使用该版本号来获取适当的数据)由于行版本的生成,启用快照隔离会在tempdb中增加额外的使用空间.会带来I/O开销的增加.
3.启用快照隔离
ALTER DATABASE CHANGE_TRACK_DB
SET ALLOW_SNAPSHOT_ISOLATION ON
GO
4.通过查询sys.change_tracking_databases来确认数据库是否以正确启用更改跟踪.
SELECT DB_NAME(DATABASE_ID) AS [DB_NAME], IS_AUTO_CLEANUP_ON, RETENTION_PERIOD, RETENTION_PERIOD_UNITS_DESC
FROM sys.change_tracking_databases
GO

5.创建测试表
USE CHANGE_TRACK_DB
GO
CREATE TABLE CHANGE_TRACKING_USER
(USERID INT NOT NULL PRIMARY KEY IDENTITY(1,1),
NAME VARCHAR(20) NOT NULL,
ADDRESS VARCHAR(100) NOT NULL)
GO
对于要打开更改跟踪以及要跟踪哪些列被跟新了的表,需要打开表的CHANGE_TRACKING选项和TRACK_COLUMNS_UPDATED选项.
ALTER TABLE CHANGE_TRACKING_USER
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED= ON)
6.查询sys.change_tracking_tables目录视图可以获得启用跟踪更改的详细信息.
SELECT OBJECT_NAME(OBJECT_ID) AS [TB_NAME], IS_TRACK_COLUMNS_UPDATED_ON
FROM sys.change_tracking_tables
GO

7.对表进行插入数据来捕获更改跟踪.
INSERT CHANGE_TRACKING_USER(NAME, ADDRESS)
VALUES(‘Kobe’,’Lakers’),
(‘Jordon’, ‘Bull’),
(‘Wade’, ‘Heat’),
(‘Howard’, ‘Magic’)
GO
8.查看正在同步的是一个函数CHANGE_TRACKING_CURRENT_VERSION(),返回的是最后提交的事务的版本号.所有发生在启用更改跟踪表中的DML操作都会照成版本号的增长.版本号用来确定更改.
SELECT CHANGE_TRACKING_CURRENT_VERSION()

9.函数CHANGE_TRACKING_MIN_VALID_VERSION()可以获得表的最小可用版本号.如果断开连接的程序不同步的时间超过了更改跟踪保留期限.那么就要对应用程序的数据进行彻底的刷新.
SELECT CHANGE_TRACKING_MIN_VALID_VERSION(OBJECT_ID(‘CHANGE_TRACKING_USER’))

10.对于更改的侦测我们可以用函数CHANGETABLE.该函数有种用法:使用CHANGES关键字来检测从指定的同步版本以来发生的更改;或者使用VERSION关键字来返回最新的更改跟踪版本.
SELECT USERID –返回的是主键
,SYS_CHANGE_OPERATION –I 代表INSERT, U代表UPDATE, D代表DELETE
,SYS_CHANGE_VERSION –返回的是版本号,因为这条数据是在同一个INSERT中添加的,所以下面的结果版本号相同
FROM CHANGETABLE(CHANGES CHANGE_TRACKING_USER, 0) A — 此函数返回的是自版本以来的更改.第一个参数是表名称

11.当收集同步信息时,使用SET TRANSACTION ISOLATION LEVEL SNAPSHOT 和BEGIN TRAN..COMMIT TRAN来封装收集的更改信息和相关的当前更改跟踪版本以及最小的可用版本.使用快照隔离允许更改跟踪的数据具有事务一致性的形式.
UPDATE CHANGE_TRACKING_USER
SET NAME = ‘Kobe Bryant’
WHERE USERID = 1
UPDATE CHANGE_TRACKING_USER
SET ADDRESS = ‘Lakers’
WHERE USERID = 4
DELETE FROM CHANGE_TRACKING_USER WHERE USERID = 2
–检查最新的版本号
SELECT CHANGE_TRACKING_CURRENT_VERSION()

12.当程序收集了自数据版本后的数据.下面可以检测自版本起发生的所有更改
SELECT USERID, SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION, SYS_CHANGE_COLUMNS
FROM CHANGETABLE(CHANGES CHANGE_TRACKING_USER, 1) AS T

SYS_CHANGE_COLUMNS列式包含从最新版本开始更新过的列的VARBINARY值,可以使用CHANGE_TRACKING_IS_COLUMN_IN_MASK函数来解释它.该函数接受个参数:表的列ID和VARBINARY值.
13.下面使用这个函数来检查NAME列和ADDRESS列是否被修改过.
SELECT USERID, –该函数返回对应的列ID
CHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(OBJECT_ID(‘CHANGE_TRACKING_USER’),’NAME’,’COLUMNID’),
SYS_CHANGE_COLUMNS) NAME_IS_CHANGED,CHANGE_TRACKING_IS_COLUMN_IN_MASK(
COLUMNPROPERTY(OBJECT_ID(‘CHANGE_TRACKING_USER’),’ADDRESS’,’COLUMNID’)
,SYS_CHANGE_COLUMNS) ADDRESS_IS_CHANGED
FROM CHANGETABLE(CHANGES CHANGE_TRACKING_USER,1) AS T
WHERE SYS_CHANGE_OPERATION = ‘U’ –确定修改的列

14.CHANGETABLE 通过VERSION 参数来返回最新的版本.
SELECT A.USERID, NAME, ADDRESS, SYS_CHANGE_VERSION
FROM CHANGE_TRACKING_USER A
CROSS APPLY CHANGETABLE(VERSION CHANGE_TRACKING_USER, (USERID), (A.USERID)) T
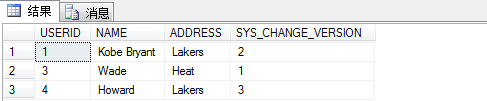
15.下面再演示一个UPDATE来演示版本的不同.
UPDATE CHANGE_TRACKING_USER
SET ADDRESS = ‘MIAMI HEAT’
WHERE USERID = 3
SELECT CHANGE_TRACKING_CURRENT_VERSION() –检查最新的版本号

SELECT A.USERID, NAME, ADDRESS, SYS_CHANGE_VERSION
FROM CHANGE_TRACKING_USER A
CROSS APPLY CHANGETABLE(VERSION CHANGE_TRACKING_USER, (USERID), (A.USERID)) T
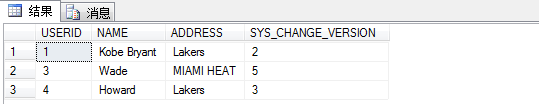
可以看到USERID=3的版本号为5,这是因为版本号是一致递增的(第11步版本号已经到4),所以现在最新的版本号位.没有修改的行版本号不变.
16.最后测试如何通过DML操作提供更改跟踪应用程序上下文信息,可以确定是哪一应用程序对那些行进行了数据修改.它的作用是如果有多个应用程序对数据源进行数据同步,这将会是有用的信息.使用CHANGE_TRACKING_CONTEXT函数来查询,函数只有一个输入参数CONTEXT,它是VARBINARY数据类型.
首先要保存上下文信息的变量,然后在CHANGE_TRACKING_CONTEXT函数中使用变量,再向更改跟踪表中插入一条新行
DECLARE @CONTEXT VARBINARY(128) = CAST(‘DS_ALEX’ AS VARBINARY(128));
WITH CHANGE_TRACKING_CONTEXT(@CONTEXT)
INSERT CHANGE_TRACKING_USER(NAME,ADDRESS)
VALUES(‘James’, ‘Heat’)
–现在查询从版本发生的所有更改.
SELECT USERID, SYS_CHANGE_OPERATION, SYS_CHANGE_VERSION, CAST(SYS_CHANGE_CONTEXT AS VARCHAR(50)) AppContext
FROM CHANGETABLE(CHANGES CHANGE_TRACKING_USER, 5) AS T

以上主要涉及了建库建表,
ALTER DATABASE ….ENABLE CHANGE_TRACKING. 启用数据库更改跟踪
CHANGE_RETENTION 和AUTO_CLEANUP 指定更改跟踪保留期限和自动清除.
查询SYS.CHANGE_TRACKING_DATABASES目录视图检查数据库更改跟踪的状态.
ALTER TABLE …ENABLE CHANGE_TRACKING
TRACK_COLUMNS_UPDATED 指定列级别更改也会被跟踪.
SYS.CHANGE_TRACKING_TABLES目录视图确认表的更改跟踪状态
一些检测更改跟踪数据的不同函数:
CHANGE_TRACKING_CURRENT_VERSION() 返回最后提交的事务版本号
CHANGE_TRACKING_MIN_VALID_VERSION() 返回更改跟踪表的最小可用版本号
CHANGETABLE:VERSION 返回最新的更改版本
CHANGES 检测自指定同步版本以来的更改
CHANGE_TRACKING_IS_COLUMN_IN_MASK 检测更改跟踪表中那些列被更新
CHANGE_TRACKING_CONTEXT 通过DML操作存储更改上下文,从而可以跟踪哪一应用程序修改了什么数据.
提供填充因子选项是为了优化索引数据存储和性能.当创建或重新生成索引时,填充因子值可确定每个叶级页上要填充数据的空间百分比,以便保留一定百分比的可用空间供以后扩展索引.例如,指定填充因子的值为 80 表示每个叶级页上将有20% 的空间保留为空,以便随着在基础表中添加数据而为扩展索引提供空间.在每个页上的索引行之间(而不是在页的末尾)保留空白区域.
填充因子值是 1 到 100 之间的百分比值,服务器范围的默认值为 0,这表示将完全填充叶级页.
注意:填充因子值 0 和 100 意义相同.
可以使用 CREATE INDEX 或 ALTER INDEX 语句来设置各个索引的填充因子值.若要修改服务器范围的默认值,请使用 sp_configure 系统存储过程.若要查看一个或多个索引的填充因子值,请使用 sys.indexes 目录视图.
重要提示:只有在创建或重新生成了索引后,才会应用填充因子.SQL Server 数据库引擎并不会在页中动态保持指定的可用空间百分比.如果试图在数据页上保持额外的空间,将有背于使用填充因子的本意,因为随着数据的输入,数据库引擎将不得不在每个页上进行页拆分,以保持填充因子所指定的可用空间百分比.
性能注意事项
1.页拆分
正确选择填充因子值可提供足够的空间以便随着向基础表中添加数据而扩展索引,从而降低页拆分的可能性.
如果向已满的索引页添加新行,数据库引擎将把大约一半的行移到新页中,以便为该新行腾出空间.这种重组称为页拆分.页拆分可为新记录腾出空间,但是执行页拆分可能需要花费一定的时间,此操作会消耗大量资源.此外,它还可能造成碎片,从而导致 I/O 操作增加.如果经常发生页拆分,可通过使用新的或现有的填充因子值来重新生成索引,从而重新分发数据.有关详细信息,请参阅重新组织和重新生成索引.
尽管采用较低的填充因子值(非 0)可减少随着索引增长而拆分页的需求,但是索引将需要更多的存储空间,并且会降低读取性能.即使对于面向许多插入和更新操作的应用程序,数据库读取次数一般也超过数据库写入次数的 5 到 10 倍.因此,指定一个不同于默认值的填充因子会降低数据库的读取性能,而降低量与填充因子设置的值成反比.例如,当填充因子的值为 50 时,数据库的读取性能会降低两倍.读取性能降低是因为索引包含较多的页,因此增加了检索数据所需的磁盘I/O 操作.
2.将数据添加到表的末尾
如果新数据在表中均匀分布,则非零填充因子对性能有利.但是,如果所有数据都添加到表的末尾,则不会填充空的空间.例如,如果索引键列是 IDENTITY 列,则新行的键将总是增加,并且行在逻辑意义上将添加到表的末尾.在这种情况下,页拆分将不会导致性能下降,因此您应当使用默认填充因子 0,或者指定填充因子 100,以便在叶级进行填充.
为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词).
通常意义上,大致为如下两类:
1,这些词应用十分广泛,在Internet上随处可见,比如“Web”一词几乎在每个网站上均会出现,对这样的词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率;
2,这类就更多了,包括了语气助词,副词,介词,连接词等,通常自身并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的“,”在“之类.举个例子来说,象“IT技术点评“,虽然其中的“IT”从我们的本意上是指“Information Technology”,事实上这种缩写也能够为大多数人接受,但对搜索引擎来说,此“IT”不过是“it”,即“它“的意思,这在英文中是一个极其常见同时意思又相当含混的词,在大多数情况下将被忽略.我们在IT技术点评中保留“IT”更多地面向“人“而非搜索引擎,以求用户能明了IT技术点评网站涉及的内容限于信息技术,虽然从SEO的角度这未必是最佳的处理方式.
了解Stop Words,在网页内容中适当地减少Stop Words出现的频率,可以有效地帮助我们提高关键词密度,而在网页Title中避免出现Stop Words往往能够让我们优化的关键词更突出.
Google stop words list:比如 I,a,about,an,are,as,at,be,by,com,de,of,on,or,that,what,when,where,who…
中文停止词:”在“,”里面“,”也“,”的“,”它“,”为“这些词都是停止词.这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉.
在 SQL Server 2005 中,可以通过将非键列添加到非聚集索引的叶级别来扩展非聚集索引的功能.通过包含非键列,可以创建覆盖更多查询的非聚集索引.这是因为非键列具有下列优点:
1.它们可以是不允许作为索引键列的数据类型.
2.在计算索引键列数或索引键大小时,数据库引擎不考虑它们.
3.当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能.这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作.
注意:当索引包含查询引用的所有列时,它通常称为”覆盖查询”.
4.键列存储在索引的所有级别中,而非键列仅存储在叶级别中.
5.使用包含性列以避免大小限制.
6.可以将非键列包含在非聚集索引中,以避免超过当前索引大小的限制(最大键列数为 16,最大索引键大小为 900 字节).数据库引擎 计算索引键列数或索引键大小时,不考虑非键列.
例如,假设要为 AdventureWorks 示例数据库的 Document 表中的以下列建立索引:
Title nvarchar(50)
Revision nchar(5)
FileName nvarchar(400)
因为 nvarchar 数据类型要求每个字符 2 个字节,所以包含这三列的索引将超过 900 字节的大小限制,多了 10 个字节 (455 * 2).使用 CREATE INDEX 语句的 INCLUDE 子句,可以将索引键定义为 (Title, Revision),将FileName 定义为非键列.这样,索引键大小将为 110 个字节 (55 * 2),并且索引仍将包含所需的所有列.下面的语句就创建了这样的索引.
USE AdventureWorks;
GO
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
带有包含性列的索引准则
1.设计带有包含性列的非聚集索引时,请考虑下列准则:
2.在 CREATE INDEX 语句的 INCLUDE 子句中定义非键列.
3.只能对表或索引视图的非聚集索引定义非键列.
4.除 text,ntext 和 image 之外,允许所有数据类型.
5.精确或不精确的确定性计算列都可以是包含性列.
6.与键列一样,只要允许将计算列数据类型作为非键索引列,从 image,ntext 和 text 数据类型派生的计算列就可以作为非键(包含性)列.
7.不能同时在 INCLUDE 列表和键列列表中指定列名.
8.INCLUDE 列表中的列名不能重复.
列大小准则
1.必须至少定义一个键列.最大非键列数为 1023 列.也就是最大的表列数减 1.
2.索引键列(不包括非键)必须遵守现有索引大小的限制(最大键列数为 16,总索引键大小为 900 字节).
3.所有非键列的总大小只受 INCLUDE 子句中所指定列的大小限制;例如,varchar(max) 列限制为 2 GB.
列修改准则,修改已定义为包含性列的表列时,要受下列限制:
1.除非先删除索引,否则无法从表中删除非键列.
2.除进行下列更改外,不能对非键列进行其他更改:将列的为空性从 NOT NULL 改为 NULL.
3.增加 varchar,nvarchar 或 varbinary 列的长度.
注意:这些列修改限制也适用于索引键列.
设计建议
重新设计索引键大小较大的非聚集索引,以便只有用于搜索和查找的列为键列.将覆盖查询的所有其他列设置为包含性非键列.这样,将具有覆盖查询所需的所有列,但索引键本身较小,而且效率高.
例如,假设要设计覆盖下列查询的索引.
USE AdventureWorks;
GO
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N’98000′ and N’99999′;
若要覆盖查询,必须在索引中定义每列.尽管可以将所有列定义为键列,但键大小为 334 字节.因为实际上用作搜索条件的唯一列是 PostalCode 列(长度为 30 字节),所以更好的索引设计应该将 PostalCode 定义为键列并包含作为非键列的所有其他列.
下面的语句创建了一个覆盖查询的带有包含性列的索引.
USE AdventureWorks;
GO
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
性能注意事项
1.避免添加不必要的列.添加过多的索引列(键列或非键列)会对性能产生下列影响:一页上能容纳的索引行将更少.这样会使 I/O 增加并降低缓存效率.
2.需要更多的磁盘空间来存储索引.特别是,将 varchar(max),nvarchar(max),varbinary(max) 或 xml 数据类型添加为非键索引列会显著增加磁盘空间要求.这是因为列值被复制到了索引叶级别.因此,它们既驻留在索引中,也驻留在基表中.
3.索引维护可能会增加对基础表或索引视图执行修改,插入,更新或删除操作所需的时间.
您应该确定修改数据时在查询性能上的提升是否超过了对性能的影响,以及是否需要额外的磁盘空间要求.
数据库快照是数据库(称为“源数据库“)的只读静态视图.在创建时,每个数据库快照在事务上都与源数据库一致.在创建数据库快照时,源数据库通常会有打开的事务.在快照可以使用之前,打开的事务会回滚以使数据库快照在事务上取得一致.
客户端可以查询数据库快照,这对于基于创建快照时的数据编写报表是很有用的.而且,如果以后源数据库损坏了,便可以将源数据库恢复到它在创建快照时的状态.
创建数据库快照的原因包括:
注意 :数据库快照与源数据库相关.因此,使用数据库快照还原数据库不能代替备份和还原策略.严格按计划执行备份仍然至关重要.如果必须将源数据库还原到创建数据库快照的时间点,请实施允许您执行该操作的备份策略.
注意 :使用数据库快照的原因,决定了数据库需要多少个并发快照,多久创建一次新快照以及将其保留多久.
管理测试数据库
在测试环境中,当每一轮测试开始时针对要包含相同数据的数据库重复运行测试协议将十分有用.在运行第一轮测试前,应用程序开发人员或测试人员可以在测试数据库中创建数据库快照.每次运行测试之后,数据库都可以通过还原数据库快照快速返回到它以前的状态.
数据库快照提供源数据库在创建快照时的只读,静态视图,不包含未提交的事务.由于数据库引擎在创建快照后运行恢复,因此未提交的事务在新近创建的数据库快照中回滚(数据库中的事务不受影响).
数据库快照与源数据库相关.数据库快照必须与数据库在同一服务器实例上.此外,如果数据库因某种原因而不可用,则它的所有数据库快照也将不可用.
快照可用于报表.另外,如果源数据库出现用户错误,还可将源数据库恢复到创建快照时的状态.丢失的数据仅限于创建快照后数据库更新的数据.此外,在对数据库进行重大更改(例如,更改表的架构或结构)之前创建数据库快照也很有用.
虽然不一定必须使用快照,但是了解其工作原理会有所帮助.数据库快照在数据页级运行.在第一次修改源数据库页之前,先将原始页从源数据库复制到快照.此过程称为“写入时复制操作“.快照将存储原始页,保留它们在创建快照时的数据记录.对已修改页中的记录进行后续更新不会影响快照的内容.对要进行第一次修改的每一页重复此过程.这样,快照将保留自创建快照后经修改的所有数据记录的原始页.
为了存储复制的原始页,快照使用一个或多个“稀疏文件“.最初,稀疏文件实质上是空文件,不包含用户数据并且未被分配存储用户数据的磁盘空间.随着源数据库中更新的页越来越多,文件的大小也不断增长.创建快照时,稀疏文件占用的磁盘空间很少.然而,由于数据库随着时间的推移不断更新,稀疏文件会增长为一个很大的文件.
下图说明了写入时复制操作.快照关系图中的浅灰色方框表示稀疏文件中尚未分配的潜在空间.收到源数据库中页的第一次更新时,数据库引擎将写入文件,操作系统向快照的稀疏文件分配空间并将原始页复制到该处.然后,数据库引擎更新源数据库中的页.下图说明了此类写入时复制操作.
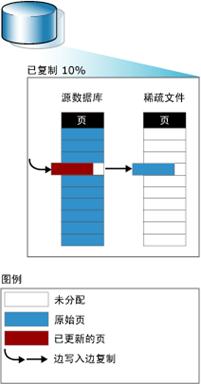
重要提示:由于数据库快照不是冗余存储,因此,它们不会防止磁盘出现错误或其他类型的损坏.为了保护数据库,非常有必要定期执行备份并测试还原计划.如果必须将源数据库还原到创建数据库快照的时间点,请实施允许您执行该操作的备份策略.
对数据库快照的读操作
对于用户而言,数据库快照似乎始终保持不变,因为对数据库快照的读操作始终访问原始数据页,而与页驻留的位置无关.如果未更新源数据库中的页,则对快照的读操作将从源数据库读取原始页.下图显示了对新创建的快照(因此其稀疏文件不包含页)的读操作.此读操作仅从源数据库读取.

更新页之后,对快照的读操作仍访问原始页,该原始页现在存储在稀疏文件中.下图说明了对访问源数据库中更新页的快照的读操作.此读操作从快照的稀疏文件中读取原始页.
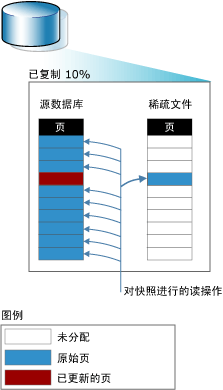
更新模式对数据库快照增长的影响
如果您的源数据库过大并且您担心磁盘空间使用量,则您应该在某个时候用新快照替换旧快照.快照理想的使用期限取决于其增长率以及可用于其稀疏文件的磁盘空间.快照所需的磁盘空间取决于在快照使用期限内源数据库中更新的不同页的数量.因此,如果大多数情况下更新重复更新的页的小子集,则随着时间的推移,增长率会降低,快照所需空间也会相对较小.相反,如果最终将所有原始页至少更新一次,则快照将会增长到源数据库的大小.如果磁盘将满,则快照会互相争用磁盘空间.如果磁盘驱动器已满,则无法将操作写入所有快照.
因此,在计划快照预计使用期限内所需空间量时,了解数据库的通常更新模式是很有用的.对于某些数据库,更新率可能相当稳定;例如,库存数据库可能每天都更新很多页,这对每天或每周替换旧快照非常有用.对于其他数据库,更新页的比例在业务周期内可能有所不同;例如,目录数据库可能通常每季度更新,会在其他时间偶尔更新;逻辑策略是在每季度更新前后创建快照.如果发生严重更新错误,允许还原更新前快照,而更新后快照用于报告下一季度的写入.
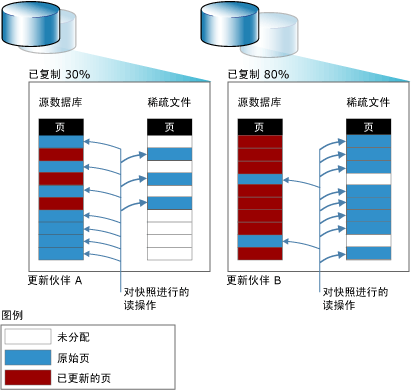
下图说明了两种相对的更新模式对快照大小的影响.更新模式 A 反映的是在快照使用期限内仅有 30% 的原始页更新的环境.更新模式 B 反映的是在快照使用期限内有 80% 的原始页更新的环境.
数据库快照的元数据
对于数据库快照,数据库元数据包括 source_database_id 属性,该属性存储在 sys.databases 目录视图的列中通常,数据库快照不公开自己的元数据,但会公开源数据库的元数据.例如,此元数据包括下列语句返回的数据:
USE <database_snapshot> SELECT * FROM sys.database_files
其中,<database_snapshot>是数据库快照的名称.
唯一的例外情况是当源数据库使用全文搜索或数据库镜像时,此时由于更改了快照元数据中的一些值,因此在快照上禁用了源数据库.
对于大多数情况,在完整恢复模式或大容量日志恢复模式下,SQL Server 2005 及更高版本要求您备份日志结尾以捕获尚未备份的日志记录.还原操作之前对日志尾部执行的日志备份称为“结尾日志备份“.
SQL Server 2005 及更高版本通常要求您在开始还原数据库前执行结尾日志备份.结尾日志备份可以防止工作丢失并确保日志链的完整性.将数据库恢复到故障点时,结尾日志备份是恢复计划中的最后一个相关备份.如果无法备份日志尾部,则只能将数据库恢复为故障前创建的最后一个备份.
并非所有还原方案都要求执行结尾日志备份.如果先前的日志备份中包含恢复点,或者您准备移动或替换(覆盖)数据库,则不一定需要结尾日志备份.并且,如果日志文件受损且无法创建结尾日志备份,则必须在不使用结尾日志备份的情况下还原数据库.最新日志备份后提交的任何事务都将丢失
备份日志尾部
结尾日志备份与任何其他日志备份类似,使用 BACKUP LOG 语句执行.建议下列情况下执行结尾日志备份:
注意:为防止出错,必须使用 NORECOVERY 选项(指定不发生回滚).
重要提示:除非数据库受损,否则不建议使用 NO_TRUNCATE.
如果数据库受损(例如,数据库无法启动),则仅当日志文件未受损,数据库处于支持结尾日志备份的状态并且不包含任何大容量日志更改时,结尾日志备份才能成功.
|
BACKUP LOG 选项 |
注释 |
|
NORECOVERY |
每当您准备对数据库继续执行还原操作时,请使用 NORECOVERY.NORECOVERY使数据库进入还原状态.这确保了数据库在结尾日志备份后不会更改. 除非同时指定 NO_TRUNCATE 或 COPY_ONLY 选项,否则将截断日志. |
|
{ CONTINUE_AFTER_ERROR | NO_TRUNCATE } |
仅当您要备份受损数据库的尾部时才能使用 NO_TRUNCATE 或CONTINUE_AFTER_ERROR. 注意:对受损数据库备份日志尾部时,日志备份中正常捕获的部分元数据可能不可用. |
在数据库损坏时创建事务日志备份
包含不完整备份元数据的结尾日志备份
结尾日志备份可捕获日志尾部,即使数据库脱机,损坏或缺少数据文件.这可能导致还原信息命令和 msdb 生成不完整的元数据.但只有元数据是不完整的,而捕获的日志是完整且可用的.
如果结尾日志备份包含不完整的元数据,则 backupset 表中的 has_incomplete_metadata 将设置为 1.此外,在RESTORE HEADERONLY 的输出中,HasIncompleteMetadata 将设置为 1.
如果结尾日志备份中的元数据不完整,则 backupfilegroup 表在结尾日志备份时将丢失文件组的大多数相关信息.大多数 backupfilegroup 表列为 NULL;只有以下几列有意义:
不使用结尾日志备份执行还原
不需要结尾日志备份的还原方案包括以下几种:
将数据库还原到先前时间点
将数据库还原到新位置
对于大多数情况,在完整恢复模式或大容量日志恢复模式下,SQL Server 2005 及更高版本要求您备份日志结尾以捕获尚未备份的日志记录.还原操作之前对日志尾部执行的日志备份称为”结尾日志备份”.
SQL Server 2005 及更高版本通常要求您在开始还原数据库前执行结尾日志备份.结尾日志备份可以防止工作丢失并确保日志链的完整性.将数据库恢复到故障点时,结尾日志备份是恢复计划中的最后一个相关备份.如果无法备份日志尾部,则只能将数据库恢复为故障前创建的最后一个备份.
并非所有还原方案都要求执行结尾日志备份.如果先前的日志备份中包含恢复点,或者您准备移动或替换(覆盖)数据库,则不一定需要结尾日志备份.并且,如果日志文件受损且无法创建结尾日志备份,则必须在不使用结尾日志备份的情况下还原数据库.最新日志备份后提交的任何事务都将丢失
备份日志尾部
结尾日志备份与任何其他日志备份类似,使用 BACKUP LOG 语句执行.建议下列情况下执行结尾日志备份:
注意:为防止出错,必须使用 NORECOVERY 选项(指定不发生回滚).
重要提示:除非数据库受损,否则不建议使用 NO_TRUNCATE.
如果数据库受损(例如,数据库无法启动),则仅当日志文件未受损,数据库处于支持结尾日志备份的状态并且不包含任何大容量日志更改时,结尾日志备份才能成功.
|
BACKUP LOG 选项 |
注释 |
|
NORECOVERY |
每当您准备对数据库继续执行还原操作时,请使用NORECOVERY.NORECOVERY 使数据库进入还原状态.这确保了数据库在结尾日志备份后不会更改. 除非同时指定 NO_TRUNCATE 或 COPY_ONLY 选项,否则将截断日志. |
|
{ CONTINUE_AFTER_ERROR | NO_TRUNCATE } |
仅当您要备份受损数据库的尾部时才能使用 NO_TRUNCATE 或CONTINUE_AFTER_ERROR. 注意:对受损数据库备份日志尾部时,日志备份中正常捕获的部分元数据可能不可用. |
在数据库损坏时创建事务日志备份
包含不完整备份元数据的结尾日志备份
结尾日志备份可捕获日志尾部,即使数据库脱机,损坏或缺少数据文件.这可能导致还原信息命令和 msdb 生成不完整的元数据.但只有元数据是不完整的,而捕获的日志是完整且可用的.
如果结尾日志备份包含不完整的元数据,则 backupset 表中的 has_incomplete_metadata 将设置为 1.此外,在RESTORE HEADERONLY 的输出中,HasIncompleteMetadata 将设置为 1.
如果结尾日志备份中的元数据不完整,则 backupfilegroup 表在结尾日志备份时将丢失文件组的大多数相关信息.大多数 backupfilegroup 表列为 NULL;只有以下几列有意义:
不使用结尾日志备份执行还原
不需要结尾日志备份的还原方案包括以下几种:
将数据库还原到先前时间点
将数据库还原到新位置
注意:应当尽量避免使用 REPLACE 选项执行还原,并且只有经验丰富的数据库管理员在慎重考虑后才能这样做.
注意:应当尽量避免使用 REPLACE 选项执行还原,并且只有经验丰富的数据库管理员在慎重考虑后才能这样做.
数据库快照捕获开始创建快照的时间点,去掉所有未提交的事务.使用数据库快照之前,应了解数据库快照对源数据库和系统环境的影响,以及快照本身存在哪些限制.
重要提示:只有 MicrosoftSQL Server 2005 Enterprise Edition 和更高版本才提供数据库快照功能.
源数据库存在的限制
只要存在数据库快照,快照的源数据库就存在以下限制:
注意:可以备份源数据库,这方面将不受数据库快照的影响.
注意:所有恢复模式都支持数据库快照.
数据库快照的限制
数据库快照存在以下限制:
注意:对数据库快照执行的 SELECT 语句不能指定 FILESTREAM 列;否则,将返回如下错误消息:由于数据移动,无法继续以 NOLOCK 方式扫描.
磁盘空间要求
数据库快照占用磁盘空间.如果数据库快照用尽了磁盘空间,将被标记为可疑,必须将其删除.(但是,源数据库不会受到影响,对其执行的操作仍能继续正常进行.)然而,与一份完整的数据库相比,快照具有高度空间有效性.快照仅需足够存储空间来存储在其生存期中更改的页.通常情况下,快照只会保留一段有限的时间,因此其大小不是主要问题.
但是,保留快照的时间越长,越有可能将可用空间用完.稀疏文件最大只能增长到创建快照时相应的源数据库文件的大小.
如果数据库快照用完了磁盘空间,则必须删除该快照.
注意 除文件空间外,数据库快照与数据库占用的资源量大致相同.
含有脱机文件组的数据库快照
当您尝试执行下列任何操作时,源数据库中的脱机文件组都将影响数据库快照:
数据库快照功能是在 MicrosoftSQL Server 2005 中新增的功能.只有 SQL Server 2005 Enterprise Edition 和更高版本才提供数据库快照功能.所有恢复模式都支持数据库快照.
数据库快照是数据库(源数据库)的只读,静态视图.多个快照可以位于一个源数据库中,并且可以作为数据库始终驻留在同一服务器实例上.创建快照时,每个数据库快照在事务上与源数据库一致.在被数据库所有者显式删除之前,快照始终存在.
与用户数据库的默认行为不同,数据库快照是通过将 ALLOW_SNAPSHOT_ISOLATION 数据库选项设置为 ON 而创建的,不需要考虑主数据库或模型系统数据库中该选项的设置.
快照可用于报表.另外,如果源数据库出现用户错误,还可将源数据库恢复到创建快照时的状态.丢失的数据仅限于创建快照后数据库更新的数据.
重要提示 :无法对脱机或损坏的数据库进行恢复.因此,为了保护数据库,非常有必要定期执行备份并测试还原计划.
注意:数据库快照与快照备份,事务的快照隔离或快照复制无关.
任何能创建数据库的用户都可以创建数据库快照.
重要提示:只有 SQL Server 2005,SQL Server 2008 和 SQL Server 2008 R2 的 Enterprise Edition提供了 SQL Server 2005 中引入的数据库快照功能.
创建数据库快照的最佳方法
下面是进行如下操作的一些最佳方法:命名数据库快照,创建它们时进行计时,限制它们的数量以及将客户端连接重新定向到快照.
命名数据库快照
创建数据库快照之前,考虑如何命名它们是非常重要的.每个数据库快照都需要一个唯一的数据库名称.为了便于管理,数据库快照的名称可以包含标识数据库的信息,例如:
例如,考虑 AdventureWorks2008R2 数据库的一系列快照.在上午 6 时和下午 6 时(基于 24 小时制)之间,以 6个小时作为间隔创建三个每日快照.每个每日快照保持 24 小时才被删除并被同一名称的新快照替换.请注意,每个快照名称指明了小时,而非天:
AdventureWorks2008R2_snapshot_0600
AdventureWorks2008R2_snapshot_1200
AdventureWorks2008R2_snapshot_1800
另外,如果这些每日快照创建的时间每天都变化,则推荐使用不太精确的命名约定,例如:
AdventureWorks2008R2_snapshot_morning
AdventureWorks2008R2_snapshot_noon
AdventureWorks2008R2_snapshot_evening
限制数据库快照的数量
随着时间的变化创建一系列快照可捕获源数据库的连续快照.每个数据库快照会一直存在直到显式删除.因为每个快照会随着原始页的更新而不断增长,所以您可能想在创建新快照后通过删除旧的快照来节省空间.
注意:如果想要还原到某个数据库快照,则需要从该数据库中删除所有其他快照.
将客户端连接到数据库快照
若要使用数据库快照,客户端需要知道它的位置.正在创建或删除另一个数据库快照时,用户可以从一个数据库快照读取.但是,如果用新快照替代现有快照,您需要将客户端重新定向到新快照.用户可以通过 SQL Server Management Studio 手动连接到数据库快照.但是,若要支持生产环境,您应该创建一个编程解决方案,该方案透明地将报表编写客户端定向到数据库的最新数据库快照.
创建数据库快照
注意:SQL Server Management Studio 不支持创建数据库快照.
创建数据库快照的唯一方式是使用 Transact-SQL.可创建数据库的任何用户都可以创建数据库快照;但是,若要创建镜像数据库的快照,您必须是 sysadmin 固定服务器角色的成员.
注意:创建数据库快照时,CREATE DATABASE 语句中不允许有日志文件,脱机文件,还原文件和不起作用的文件.
A. 对 AdventureWorks2008R2 数据库创建快照
此示例对 AdventureWorks2008R2 数据库创建数据库快照.快照名称 AdventureWorks2008R2_dbss_1800 及其稀疏文件的名称 AdventureWorks2008R2_data_1800.ss 指明了创建时间 6 P.M.(1800 小时).
CREATE DATABASE AdventureWorks2008R2_dbss1800 ON
( NAME = AdventureWorks2008R2_Data, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/Data/AdventureWorks2008R2_data_1800.ss’ )
AS SNAPSHOT OF AdventureWorks2008R2;
GO
注意:示例中随意使用了扩展名 .ss.
B. 对 Sales 数据库创建快照
此示例对 Sales 数据库创建数据库快照 sales_snapshot1200.
–Creating sales_snapshot1200 as snapshot of the
–Sales database:
CREATE DATABASE sales_snapshot1200 ON
( NAME = SPri1_dat, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/data/SPri1dat_1200.ss’),
( NAME = SPri2_dat, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/data/SPri2dt_1200.ss’),
( NAME = SGrp1Fi1_dat, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/data/SG1Fi1dt_1200.ss’),
( NAME = SGrp1Fi2_dat, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/data/SG1Fi2dt_1200.ss’),
( NAME = SGrp2Fi1_dat, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/data/SG2Fi1dt_1200.ss’),
( NAME = SGrp2Fi2_dat, FILENAME =
‘C:/Program Files/Microsoft SQL Server/MSSQL10_50.MSSQLSERVER/MSSQL/data/SG2Fi2dt_1200.ss’)
AS SNAPSHOT OF Sales
GO
页面还原与使用完整恢复模式或大容量日志恢复模式的 SQL Server 数据库相关.只有读/写文件组支持页面还原.
页面还原的目的是还原一个或多个损坏的页,而不还原整个数据库.通常,要进行还原的页已经由于在访问该页时遇到错误而标记为“可疑“.可疑页在 msdb 数据库的 suspect_pages 表中进行了标识.
注意:并非所有的页面错误都需要还原.缓存数据(例如辅助索引)中可能出现的问题可以通过重新计算这些数据来解决.例如,如果数据库管理员删除一个辅助索引,然后再重新生成一个辅助索引,则损坏的数据虽然已修复,但并没有在suspect_pages 表中反映出这一情况
可以立即还原多个数据库页.日志文件备份应用于包含要恢复的页的所有数据库文件.与文件还原中一样,每次传递日志重做,前滚集都会前进一步.
页面还原用于修复隔离的损坏页.还原和恢复少量页面的速度可能比还原一个文件更快,因此减少了还原操作中处于脱机状态的数据量.然而,如果文件中要还原的不只是少量页面,则通常还原整个文件更为有效.例如,如果某个设备上的大量页都指出此设备有未解决的故障;不妨考虑还原该文件(可以还原到另一位置)并修复该设备.
页面还原方案
SQL Server 2005 和更高版本的所有 Edition 都支持在数据库脱机时还原页面(“脱机页面还原“).在 SQL Server 2005 Enterprise Edition 和更高版本中,如果页面还原过程中数据库处于联机状态,则数据库将保持联机状态.在数据库处于在线状态时还原和恢复页面的行为称作“在线页面还原“.
这些页面还原方案包括:
注意:联机还原会尝试更新元数据,如果涉及重要的页面,则该更新可能会失败.如果联机还原尝试失败,则必须执行脱机还原.
页面还原利用了 SQL Server 2005 和更高版本中改进的页级错误报告(包含页校验和)和跟踪.通过校验和或残缺写操作检测为已损坏的页(“损坏页“)可以通过在 RESTORE 语句中指定这些页进行还原.页面还原仅适用于还原损坏的页数量较少的情况.RESTORE 语句中指定的每个页将由指定备份集中的页替换.还原的页必须恢复到与数据库一致的状态.仅还原显式指定的页.
页面还原的限制
仅可以还原数据库页.页面还原不能用于还原下列内容:
如果无法还原单个页,则必须使用现有的完整数据库备份或者完整文件,或文件组备份.
注意:如果要还原的页具有特殊用途(如元数据页),则联机页面还原将失败.在这些情况下,请尝试脱机页面还原.
还原页的要求
页面还原需要符合下列要求:
大容量日志恢复模式和页面还原
对于使用大容量日志恢复模式的数据库,页面还原还有下列附加条件:
基本页面还原语法
若要在 RESTORE DATABASE 语句中指定一页,需要知道该页所在文件的文件 ID 和该页的页 ID.所需语法如下:
RESTORE DATABASE database_name
PAGE = ‘file:page [ ,…n ]‘ [ ,…n ]
FROM <backup_device> [ ,…n ]
WITH NORECOVERY
页面还原的过程
页面还原的基本步骤如下:
1.获取要还原的损坏页的页 ID.校验和或残缺写错误将返回页 ID,并提供指定页所需的信息.若要查找损坏页的页 ID,请使用下列任一来源.
|
页 ID 源 |
主题 |
|
msdb..suspect_pages |
了解和管理 suspect_pages 表 |
|
错误日志 |
查看 SQL Server 错误日志 |
|
事件跟踪 |
监视事件 |
|
DBCC |
DBCC (Transact-SQL) |
|
WMI 提供程序 |
WMI Provider for Server Events Concepts |
2.从包含页的完整数据库备份,文件备份或文件组备份开始进行页面还原.在 RESTORE DATABASE 语句中,使用 PAGE子句列出所有要还原的页的页 ID.
PAGE = ‘file:page [ ,…n ]‘
3.应用最近的差异.
4.应用后续日志备份.
5.创建新的数据库日志备份,使其包含已还原页的最终 LSN,即最后还原的页脱机的时间点.设置为顺序中首先还原的最终 LSN 是重做目标 LSN.包含该页的文件的联机前滚可以在重做目标 LSN 处停止.若要了解文件的当前重做目标LSN,请查看 sys.master_files 的 redo_target_lsn 列
6.还原新的日志备份.应用这个新的日志备份后,就完成了页面还原,可以开始使用页了.
注意:此顺序与文件还原顺序类似.事实上,页面还原和文件还原都可以在相同的顺序中执行.
示例
以下示例使用 NORECOVERY 还原文件 B 的四个损坏页.随后,将使用 NORECOVERY 应用两个日志备份,然后是结尾日志备份(使用 RECOVERY 还原).
重要提示:如果损坏的页存储了重要的数据库元数据,则可能必须执行脱机页面还原顺序.若要执行脱机还原,则必须使用WITH NORECOVERY 备份事务日志.
以下示例执行联机还原.此示例中,文件 B 的文件 ID 为 1,损坏的页的页 ID 分别为 57,202,916 和 1016.
RESTORE DATABASE <database> PAGE=’1:57, 1:202, 1:916, 1:1016′
FROM <file_backup_of_file_B>
WITH NORECOVERY;
RESTORE LOG <database> FROM <log_backup>
WITH NORECOVERY;
RESTORE LOG <database> FROM <log_backup>
WITH NORECOVERY;
BACKUP LOG <database> TO <new_log_backup>
RESTORE LOG <database> FROM <new_log_backup> WITH RECOVERY;
GO
在一个产品介绍网站中查询产品时,由于产品的介绍性文字可能会很长,如果使用对产品介绍字段使用like进行模糊查询,性能肯定会是问题.那么如何解决这个问题呢?第一个想法就是使用全文索引.那么全文索引是什么,应该如何应用,在应用的过程中又应该注意哪些事情呢?
1.是什么:全文索引为在字符串数据中进行复杂的词搜索提供有效支持.全文索引存储关于重要词和这些词在特定列中的位置的信息.全文查询利用这些信息,可快速搜索包含具体某个词或一组词的行.
全文索引包含在全文目录中.每个数据库可以包含一个或多个全文目录.一个目录不能属于多个数据库,而每个目录可以包含一个或多个表的全文索引.一个表只能有一个全文索引,因此每个有全文索引的表只属于一个全文目录.
全文目录和索引不存储在它们所属的数据库中.目录和索引由 Microsoft 搜索服务分开管理.
全文索引必须在基表上定义,而不能在视图,系统表或临时表上定义.
依据上面的描述,可以做这样一个比喻.大家大概都见过档案柜,档案柜是将各种档案按照分类登记在档案索引卡上,这个档案柜中的就象建立的全文索引,通过这些档案索引卡可以迅速定位你要查找的卷宗所在的位置.如果不建立这些索引卡,如果卷宗数量不多还好,一旦档案数量很多的时候显然很难找到期望的卷宗,这就类似使用LIKE的情形.
全文索引和普通索引的区别:
|
普通SQL 索引 |
全文索引 |
|
存储时受定义它们所在的数据库的控制 |
存储在文件系统中,但通过数据库管理 |
|
每个表允许有若干个普通索引 |
每个表只允许有一个全文索引 |
|
当对作为其基础的数据进行插入,更新或删除时,它们会自动更新 |
将数据添加到全文索引称为填充,全文索引可通过调度或特定请求来请求,也可以在添加新数据时自动发生 |
|
不分组 |
在同一个数据库内分组为一个或多个全文目录 |
|
使用SQL Server企业管理器,向导或Transact-SQL语句创建和除去 |
使用SQL Server企业管理器,向导或存储过程创建,管理和除去 |
2.怎么用
a.返回包含字符串 “sea” 或 “bread” 的所有分类描述.
Use Northwind
Select * from categories
where contains( description, ‘ “sea*” or “bread*” ‘)
b.搜索产品描述中含有与 bread,candy,dry 和 meat 相关的词语的所有产品类别,如breads,candies,dried 和 meats 等.
USE Northwind
GO
SELECT CategoryName
FROM Categories
WHERE FREETEXT (Description, ‘sweetest candy bread and dry meat’ )
GO
3.建议
a.仔细考虑维护全文索引的方式
维护全文索引有三种方式:
b.所使用的方法取决于许多因素,如 CPU 和可用的内存,数据更改的数量和速度,可用磁盘空间的大小,以及当前全文索引的重要性等.以下建议可作为选择维护方式时的参考.
不过即使选择好作业类型后,也应该给调度全文索引的时机进行恰当的规划.由于表中数据的改变会影响全文索引内容,所以频繁的更新数据的表不太适合进行全文索引.同时可以把调度填充全文索引的时间放在系统比较空闲的时候,而且应该考虑到进行填充可能的时间.比如你可以把填充的时间定在每天晚上0:00,这个时候应该相对空闲一些,不过一般情况下应该差不多吧).
另外应该模拟客户处可能的数据量做个填充实验,以便对填充索引的时间长度有所估计.
如何恢复到快照结果,说明恢复操作的限制,并提供指向恢复过程的链接.作为从备份中还原联机数据库的替代方法,任何对源数据库具有 RESTORE DATABASE 权限的用户均可将该数据库恢复到创建数据库快照时的状态.当联机源数据库中的数据损坏时,恢复到最近的快照可能比较合适.但是,请确保该快照是在发生错误之前创建的,并且数据库尚未损坏.例如,恢复操作可以恢复最近出现的严重用户错误,如删除表.
通过从稀疏文件中将写入时复制的页复制回源数据库,恢复操作将覆盖自快照创建以来对源数据库进行的更新.只有更新过的页才会被覆盖.恢复操作随后会覆盖旧的日志文件,并重建日志.因此,以后无法将恢复后的数据库前滚到出现用户错误时的状态,并且自快照创建以来对数据库进行的更改将丢失.恢复后的数据库的元数据与创建快照时的元数据相同.
恢复到某个快照还会删除所有全文目录.
对恢复的限制
下列情况不支持恢复:
在恢复数据库之前,注意下列事项:
将数据库恢复到数据库快照
数据库快照不是冗余存储,因此,不针对磁盘错误或其他类型的损坏提供任何保护功能.但是,如果在联机数据库中发生用户错误,则可以将数据库恢复到发生错误之前的数据库快照.
重要提示:为了保护数据库,非常有必要定期执行备份并测试还原计划.如果必须将源数据库还原到创建数据库快照的时间点,请实施允许您执行该操作的备份策略.
恢复的数据库会覆盖原来的源数据库.恢复到快照将删除所有全文目录.
注意:在恢复操作过程中,快照和源数据库都不可用.源数据库和快照都标记为”还原中”.如果在恢复操作期间发生错误,则数据库在重新启动后,将尝试完成恢复操作.
注意:已恢复的数据库将保留数据库快照的权限和配置(例如,数据库所有者和恢复模式).
A. 恢复 AdventureWorks2008R2 数据库的快照
此示例假定 AdventureWorks2008R2 数据库当前只存在一个快照.
USE master;
— Reverting AdventureWorks2008R2 to AdventureWorks2008R2_dbss1800
RESTORE DATABASE AdventureWorks2008R2 FROM
DATABASE_SNAPSHOT = ‘AdventureWorks2008R2_dbss1800’;
GO
B. 恢复 Sales 数据库的快照
此示例假定 Sales 数据库当前存在两个快照:sales_snapshot0600 和 sales_snapshot1200.此示例删除了较旧的快照并将数据库恢复到较新的快照.
–Test to see if sales_snapshot0600 exists and if it
— does, delete it.
IF EXISTS (SELECT dbid FROM sys.databases
WHERE NAME=’sales_snapshot0600′)
DROP DATABASE SalesSnapshot0600;
GO
— Reverting Sales to sales_snapshot1200
USE master;
RESTORE DATABASE Sales FROM DATABASE_SNAPSHOT = ‘sales_snapshot1200’;
GO
数据库快照使用一个或多个“稀疏文件“来存储数据.创建数据库快照期间,可以使用 CREATE DATABASE 语句中的文件名来创建稀疏文件.这些文件名存储在 sys.master_files 中的 physical_name 列中.
注意:在 sys.database_files 中(无论是在源数据库中还是在快照中),physical_name 列中始终包含源数据库文件的名称.
稀疏文件是 NTFS 文件系统的一项功能.最初,稀疏文件不包含用户数据,因为未向其分配磁盘空间用来存储用户数据.
首次创建稀疏文件时,稀疏文件占用的磁盘空间非常少.随着数据写入稀疏文件,NTFS 会逐渐分配磁盘空间.稀疏文件可能会占用非常大的磁盘空间.如果数据库快照用尽了空间,将被标记为可疑,必须将其删除.但是,源数据库不会受到影响;对其执行的操作仍能继续正常进行.
稀疏文件按 64 KB 的增量增长;因此,磁盘上稀疏文件的大小始终是 64 KB 的倍数.根据从源数据库复制的页数,最新增长的 64 KB 可存放一到八个 8 KB 页.这意味着稀疏文件的大小一般来说会稍大于页实际填充的空间.