DataGuard 理论知识
1. Oracle的高级特性:
1. RAC, Data Gurad, Stream是Oracle高可用性体系中的三种工具,每个工具既可以独立应用,也可以相互配合,它们各自的侧重点不同,适用场景也不同;
2. RAC它的强项在于解决硬件单点故障和负载均衡,因此RAC方案常用于7*24的核心系统,但RAC方案中的数据只有一份,尽管可以通过RAID等机制避免存储故障,但是数据本身是没有冗余的,容易形成数据的单点故障;
3. Data Gurad通过冗余数据来提供数据保护,Data Gurad通过日志同步机制保证冗余数据和主数据之前的同步,这种同步可以是实时,延时,同步,异步多种形式.Data Gurad常用于异地容灾和小企业的高可用性方案,虽然可以在Standby机器上执行只读查询,从而分散Primary数据库的性能压力,但是Data Gurad决不是性能解决方案;
4. Stream是以Oracle Advanced Queue为基础实现的数据同步,提供了多种级别的灵活配置,并且Oracle提供了丰富的API等开发支持,Stream更适用在应用层面的数据共享.现在已经被Oracle GlodenGate工具取代;
2. DataGuard的原理及优点:
1. 在Data Gurad环境中,至少有两个数据库,一个处于Open状态对外提供服务,这个数据库叫作Primary Database.第二个处于恢复状态,叫作Standby Database.运行时primary Database对外提供服务,用户在Primary Database上进行操作,操作被记录在联机日志和归档日志中,这些日志通过网络传递给Standby Database.这个日志会在Standby Database上重演,从而实现Primary Database 和Standby Database 的数据同步;
2. Oracle Data Gurad对这一过程进一步的优化设计,使得日志的传递,恢复工作更加自动化,智能化,并且提供一系列参数和命令简化了DBA工作.如果是可预见因素需要关闭Primary Database,比如软硬件升级,可以把 Standby Database切换为Primary Database继续对外服务,这样即减少了服务停止时间,并且数据不会丢失.如果异常原因导致Primary Database不可用,也可以把Standby Database强制切换为Primary Database继续对外服务 ,这时数据损失成都和配置的数据保护级别有关系.因此Primary和Standby只是一个角色概念,并不固定在某个数据库中;
3. DataGuard结构:
1. DG架构可以按照功能分成3个部分:
1. 日志发送 (Redo Send);
2. 日志接收 (Redo Receive);
3. 日志应用 (Redo Apply);
2. 日志发送(Redo Send):
1. Primary Database运行过程中,会源源不断地产生Redo日志,这些日志需要发送到Standy Database.这个发送动作可以由Primary Database的LGWR或者ARCH进程完成,不同的归档目的地可以使用不同的方法,但是对于一个目的地,只能选用一种方法.选择哪个进程对数据保护能力和系统可用性有很大区别;
2. 使用ARCH进程:
1. Primary Database不断产生Redo Log,这些日志被LGWR进程写到联机日志;
2. 当一组联机日志被写满后,会发生日志切换(Log Switch),并且会触发本地归档,本地归档位置是采用LOG_ARCHIVE_DEST_1=’LOCATION=/path’这种格式定义的;
3. 完成本地归档后,联机日志就可以被覆盖重用;
4. ARCH进程通过Net把归档日志发送给Standby Database的RFS(Remote File Server)进程;
5. Standby Database端的RFS进程把接收的日志写入到归档日志(用ARCH模式传输不写Standby Redologs,直接保存成归档日志文件存放于Standby端);
6. Standby Database端的MRP(Managed Recovery Process)进程(Redo Apply)或者LSP进程(SQL Apply)在Standby Database上应用这些日志,进而同步数据;
1. 逻辑Standby接收后将其转换成SQL语句,在Standby数据库上执行SQL语句实现同步,这种方式叫SQL Apply;
2. 物理Standby接收完Primary数据库生成的REDO数据后,以介质恢复的方式实现同步,这种方式也叫Redo Apply;
3. 创建逻辑Standby数据库要先创建一个物理Standby数据库,然后再将其转换成逻辑Standby数据库;
7. 使用ARCH进程传递最大问题在于:Primary Database只有在发生归档时才会发送日志到Standby Database.如果Primary Database异常宕机,联机日志中的Redo内容就会丢失,因此使用ARCH进程无法避免数据丢失的问题,要想避免数据丢失,就必须使用LGWR,而使用LGWR又分SYNC(同步)和ASYNC(异步)两种方式;
8. 在缺省方式下,Primary Database使用的是ARCH进程;
3. 使用LGWR进程的SYNC方式:
1. Primary Database产生的Redo日志要同时写到联机日志文件和网络.也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(LGWR Network Server Process),再由LNSn进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作;
2. LGWR必须等待写入本地联机日志文件操作和通过LNSn进程的网络传送都成功,Primary Database上的事务才能提交,这也是SYNC的含义所在;
3. Standby Database的RFS进程把接收到的日志写入到Standby Redo Log日志中;
4. Primary Database的日志切换也会触发Standby Database上的日志切换,即Standby Database对Standby Redo Log的归档,然后触发Standby Database的MRP或者LSP进程恢复归档日志;
5. 因为Primary Database的Redo是实时传递的,于是Standby Database端可以使用两种恢复方法:
1. 实时恢复(Real-Time Apply):只要RFS把日志写入Standby Redo Log就会立即进行恢复;
2. 归档恢复:在完成对Standby Redo Log归档才触发恢复;
6. Primary Database默认使用ARCH进程,如果使用LGWR进程必须明确指定.使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR进程会抛出错误.如:ALTER SYSTEM SET LOG_ARCHIVE_DEST_2 = ‘SERVICE=
4. 使用LGWR进程的ASYNC方式:
1. 使用LGWR SYNC方法的可能问题在于,如果日志发送给Standby Database过程失败,LGWR进程就会报错.也就是说Primary Database的LGWR进程依赖于网络状况,有时这种要求可能过于苛刻,这时就可以使用LGWR ASYNC方式;
2. Primary Database一段产生Redo日志后,LGWR把日志同时提交给日志文件和本地LNS进程,但是LGWR进程只需成功写入日志文件就可以,不必等待LNSn进程的网络传送成功;
3. LNSn进程异步地把日志内容发送到Standby Database.多个LNSn进程可以并发发送;
4. Primary Database的Online Redo Log写满后发生Log Switch,触发归档操作,也触发Standby Database对Standby Database对Standby Redo Log的归档,然后触发MRP或者LSP进程恢复归档日志;
5. 因为LGWR进程不会等待LNSn进程的响应结果,所以配置LGWR ASYNC方式时不需要NET_TIMEOUT参数.如:ALTER SYSTEM SET LOG_ARCHIVE_DEST_2 = ‘SERVICE=
3. 日志接收(Redo Receive):
1. Standby Database的RFS(Remote File Server)进程接收到日志后,就把日志写到Standby Redo Log或者Archived Log文件中,具体写入哪个文件,取决于Primary的日志传送方式和Standby database的位置;
2. 如果写到Standby Redo Log文件中,则当Primary Database发生日志切换时,也会触发Standby Database上的Standby Redo Log的日志切换,并把这个Standby Redo Log归档.如果是写到Archived Log,那么这个动作本身也可以看作是个归档操作;
3. 在日志接收中,需要注意的是归档日志会被放在什么位置:
1. 如果配置了STANDBY_ARCHIVE_DEST参数,则使用该参数指定的目录;
2. 如果某个LOG_ARCHIVE_DEST_n参数明确定义了VALID_FOR=(STANDBY_LOGFILE,*)选项,则使用这个参数指定的目录;
3. 如果数据库的COMPATIBLE参数大于等于10.0,则选取任意一个LOG_ARCHIVE_DEST_n的值;
4. 如果STANDBY_ARCHIVE_DEST和LOG_ARCHIVE_DEST_n参数都没有配置,使用缺省的STANDBY_ARCHIVE_DEST参数值,这个缺省值是$ORACLE_HOME/dbs/arc;
4. 日志应用(Redo Apply):
1. 日志应用服务,就是在Standby Database上重演Primary Database日志,从而实现两个数据库的数据同步;
2. 根据Standby Database重演日志方式的不同,可分为物理Standby(Physical Standby)和逻辑Standby(Logical Standby):
1. Physical Standby使用的是Media Recovery技术,在数据块级别进行恢复,这种方式没有数据类型的限制,可以保证两个数据库完全一致;Physical Standby数据库只能在Mount状态下进行恢复,也可以是打开,但只能已只读方式打开,并且打开时不能执行恢复操作;
2. Logical Standby使用的是Logminer技术,通过把日志内容还原成SQL语句,然后SQL引擎执行这些语句,Logminer Standby不支持所有数据类型,可以在视图DBA_LOGSTDBY_UNSUPPORTED中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致;Logical Standby数据库可以在恢复的同时进行读写操作;
3. Standby数据库的相关进程读取接收到的REDO数据(可能来自于Standby端的归档文件,也可能来自于Standby Redologs),再将其写入Standby数据库.保存之后数据又是怎么生成的呢?两种方式:物理Standby通过REDO应用,逻辑Standby通过SQL应用;
4. 根据Redo Apply发生的时间可以分成两种:
1. 实时应用(Real-Time Apply):这种方式必须Standby Redo Log,每当日志被写入Standby Redo Log时,就会触发恢复,使用这种方式的好处在与可以减少数据库切换(Switchover或者Failover)的时间,因为切换时间主要用在剩余日志的恢复上;
2. 归档时应用,这种方式在Primary Database发生日志切换,触发Standby Database归档操作,归档完成后触发恢复,这也是默认的恢复方式;
3. 如果是Physical Standby,可以使用下面命令启用Real-Time:ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE;
4. 如果是Logical Standby,可以使用下面命令启用Real-Time:ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
5. 查看是否使用Real-Time apply:SELECT RECOVERY_MODE FROM v$archive_dest_status;
6. 查看Standby Database接收日志的状态:SELECT process, status, thread#, sequence#, client_pid FROM v$managed_standby;
4. 数据保护模式:
1. Data Guard允许定义3种数据保护模式,分别是最大保护(Maximum Protection),最大可用(Maximum Availability)和最大性能(Maximum Performance);
2. 最大保护(Maximum Protection):
1. 这种模式能够确保绝无数据丢失.要实现这一步当然是有代价的,它要求所有的事务在提交前其REDO不仅被写入到本地的Online Redologs,还要同时写入到Standby数据库的Standby Redologs,并确认REDO数据至少在一个Standby数据库中可用(如果有多个的话),然后才会在Primary数据库上提交.如果出现了什么故障导致Standby数据库不可用的话(比如网络中断),Primary数据库会被Shutdown,以防止数据丢失;
2. 使用这种方式要求Standby Database必须配置Standby Redo Log,而Primary Database必须使用LGWR,SYNC,AFFIRM方式归档到Standby Database;
3. 最高可用性(Maximum availability):
1. 这种模式在不影响Primary数据库可用前提下,提供最高级别的数据保护策略.其实现方式与最大保护模式类似,也是要求本地事务在提交前必须至少写入一台Standby数据库的Standby Redologs中,不过与最大保护模式不同的是,如果出现故障导致Standby数据库无法访问,Primary数据库并不会被Shutdown,而是自动转为最高性能模式,等Standby数据库恢复正常之后,Primary数据库又会自动转换成最高可用性模式;
2. 这种方式虽然会尽量避免数据丢失,但不能绝对保证数据完全一致.这种方式要求Standby Database必须配置Standby Redo Log,而Primary Database必须使用LGWR,SYNC,AFFIRM方式归档到Standby Database;
4. 最高性能(Maximum performance):
1. 缺省模式,这种模式在不影响Primary数据库性能前提下,提供最高级别的数据保护策略.事务可以随时提交,当前Primary数据库的REDO数据至少需要写入一个Standby数据库,不过这种写入可以是不同步的.如果网络条件理想的话,这种模式能够提供类似最高可用性的数据保护,而仅对Primary数据库的性能有轻微影响.这也是创建Standby数据库时,系统的默认保护模式;
2. 这种方式可以使用LGWR ASYNC或者ARCH进程实现,Standby Database也不要求使用Standby Redo Log;
5. 修改数据保护模式步骤:
1. 关闭数据库,重启到Mount状态,如果是RAC,需要关闭所有实例,然后只启动一个实例到mount状态;
2. 修改到日志传输参数:ALTER SYSTEM SET LOG_ARCHIVE_DEST_2 = ‘SERVICE=
3. 修改模式:ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE {PROTECTION | AVAILABILITY | PERFORMANCE};
4. 打开数据库:ALTER DATABASE OPEN;
5. 确认修改数据保护模式:SELECT protection_mode, protection_level FROM v$database;
5. 自动裂缝检测和解决:
1. 当Primary Database的某些日志没有成功发送到Standby Database,这时候发生饿了归档裂缝(Archive Gap);
2. 缺失的这些日志就是裂缝(Gap).Data Guard能够自动检测,解决归档裂缝,不需要DBA的介入.这需要配置FAL_CLIENT,FAL_SERVER这两个参数(FAL:Fetch Archive Log);
3. 从FAL这个名字可以看出,这个过程是Standby Database主动发起的”取”日志的过程,Standby Database就是FAL_CLIENT.它是从FAL_SERVER中取这些Gap,10g中,这个FAL_SERVER可以是Primary Database, 也可以是其它的Standby Database;如:FAL_SERVER=’PR1,ST1,ST2’;
4. FAL_CLIENT和FAL_SERVER两个参数都是Oracle Net Name.FAL_CLIENT通过网络向FAL_SERVER发送请求,FAL_SERVER通过网络向FAL_CLIENT发送缺失的日志.但是这两个连接不一定是一个连接.因此FAL_CLIENT向FAL_SERVER发送请求时,会携带FAL_CLIENT参数值,用来告诉 FAL_SERVER应该向哪里发送缺少的日志.这个参数值也是一个Oracle Net Name,这个Name是在FAL_SERVER上定义的,用来指向FAL_CLIENT;
5. DBA也可以手工解决,具体操作步骤如下:
1. 查看是否有日志GAP:SELECT UNIQUE THREAD#, MAX(SEQUENCE#) OVER(PARTITION BY THREAD#) LAST FROM V$ARCHIVED_LOG;
2. SELECT THREAD#, LOW_SEQUENCE#, HIGH_SEQUENCE# FROM V$ARCHIVE_GAP;
3. 如果有,则拷贝过来;
4. 手工的注册这些日志:ALTER DATABASE REGISTER LOGFILE ‘/path’;
6. 指定日志发送对象:
1. VALID_FOR属性指定传输及接收对象:
1. LOG_ARCHIVE_DEST_n参数中的VALID_FOR属性,用来指定传输的内容.从字面理解VALID_FOR就是基于哪些有效;
2. 该属性有两个参数值需要指定:REDO_LOG_TYPE和DATABASE_ROLE,我们基本上可以将其理解为:发送指定角色生成的指定类型的日志文件,该参数的主要目的是为了确保一旦发生角色切换操作后数据库的正常运转;
1. REDO_LOG_TYPE:可设置为ONLINE_LOGFILE,STANDBY_LOGFILE,ALL_LOGFILES;
2. DATABASE_ROLE:可设置为PRIMARY_ROLE,STANDBY_ROLE,ALL_ROLES;
3. VALID_FOR参数默认值是VALID_FOR=(ALL_LOGFILES,ALL_ROLES);
4. 推荐手动设置该参数而不要使用默认值,在某些情况下默认的参数值不一定合适,如逻辑Standby在默认情况下就处于OPEN READ WRITE模式,不仅有REDO数据而且还包含多种日志文件(Online Redologs,Archived Redologs,Standby Redologs);
5. 默认情况下,逻辑Standby数据库生成的归档文件和接收到的归档文件在相同的路径下,这既不便于管理,也极有可能带来一些隐患.建议对每个LOG_ARCHIVE_DEST_n参数设置合适的VALID_FOR属性.本地生成的归档文件和接收到的归档文件最好分别保存于不同路径下;
2. 通过DB_UNIQUE_NAME属性指定数据库:
1. DB_UNIQUE_NAME属性是10g版本新增加的一个关键字,在之前版本并没有这一说法.该属性的作用是指定唯一的Oracle数据库名称,也正因有了DB_UNIQUE_NAME,REDO数据在传输过程中才能确认传输到 DBA希望被传输到的数据库上;
2. 当然要确保REDO数据被传输到指定服务器,除了在LOG_ARCHIVE_DEST_n参数中指定正确 DB_UNIQUE_NAME属性之外,还有一个初始化参数LOG_ARCHIVE_CONFIG也需要进行正确的配置;
3. 该参数除了指定 Data Guard环境中的唯一数据库名外,还包括几个属性,用来控制REDO数据的传输和接收:
1. SEND:允许数据库发送数据到远端;
2. RECEIVE:允许Standby接收来自其它数据库的数据;
3. NOSEND,NORECEIVE:就是禁止喽;
4. 设置Primary数据库不接收任何归档数据,可以做如下的设置:LOG_ARCHIVE_CONFIG=’NORECEIVE,DG_CONFIG=(
5. 如果做了如上的设置,如果该服务器发生了角色切换,那它也没有接收REDO数据的能力;
7. Data Guard环境应配置的初始化参数:
1. Primary角色相关的初始化参数:
1. DB_NAME:要保持同一个Data Guard中所有数据库DB_NAME相同;
2. DB_UNIQUE_NAME:为每一个数据库指定一个唯一的名称,该参数一经指定不会再发生变化,除非DBA主动修改它,需要重启数据库服务;
3. LOG_ARCHIVE_CONFIG:该参数用来控制从远端数据库接收或发送REDO数据,通过DG_CONFIG属性列出同一个Data Guard中所有DB_UNIQUE_NAME(含Primary数据库和Standby数据库),以逗号分隔;
1. SEND/NOSEND属性控制是否可以发送;
2. RECEIVE/NORECEIVE属性控制是否能够接收;
3. 例如:LOG_ARCHIVE_CONFIG=’DG_CONFIG=(
4. LOG_ARCHIVE_DEST_n:归档文件的生成路径,该参数非常重要,并且属性和子参数也特别多:
1. LOCATOIN|SERVICE:指定目标是本地还是网络位置;
2. MANDATORY|OPTIONAL:指定是否强制写到目标位置,默认是OPTIONAL;
3. DELAY(mins):指定间隔多久应用接收到的日志,默认是30Mins;
4. ARCH|LGWR:指定使用ARCH进程传输归档日志还是LGWR进程传输在线联机日志,默认是ARCH;
5. SYNC|ASYNC:指定是同步把redo log同步写到备机还是异步写,默认是ASYNC;
6. AFFIRM|NOAFFIRM:指定RTS(Redo Transport Service)使用同步还是异步方式写磁盘,缺省是NOARRIRM;
7. NET_TIMEOUT(s):指定超时时间,默认是180s;
8. VALID_FOR:指定传输及接受对象;
9. DB_UNIQUE_NAME:指定目标数据库的unique name;
10. REOPEN指定时间后再次尝试归档:
1. 使用REOPEN=seconds(默认为300秒)属性,在指定时间重复尝试向归档目的地进行归档操作,如果该参数值设置为0,则一旦失败就不会再尝试重新连接并发送,直到下次REDO数据再被归档时会重新尝试;
2. 例如,设置 REOPEN为100 秒:LOG_ARCHIVE_DEST_2=’SERVICE=DavePrimary LGWR ASYNC REOPEN=100′;
11. ALTERNATE指定替补的归档目的地:ALTERNATE属性定义一个替补的归档目的地,所谓替补就是一旦主归档目的地因各种原因无法使用,则临时向ALTERNATE属性中指定的路径写;
1. 例如:LOG_ARCHIVE_DEST_1=’LOCATION=/disk1 ALTERNATE=LOG_ARCHIVE_DEST_2′;
2. LOG_ARCHIVE_DEST_STATE_1=ENABLE;
3. LOG_ARCHIVE_DEST_2=’LOCATION=/disk2′;
4. LOG_ARCHIVE_DEST_STATE_2=ALTERNATE;
5. 上述参数设置归档路径为/disk1,当/disk1路径下无法成功归档时,自动尝试向/disk2路径下归档文件;
12. 从功能上来看,REOPEN与ALTERNATE是有一定重复的,不过需要注意一点,REOPEN属性比ALTERNATE属性的优先级要高,如果你指定REOPEN属性的值>0,则LGWR(或ARCn)进程会首先尝试向主归档目的地写入,直到达到最大重试次数,如果仍然写入失败,才会向ALTERNATE属性指定的路径写;
13. MAX_FAILURE控制失败尝试次数:
1. 用REOPEN指定失败后重新尝试的时间周期,MAX_FAILURE则控制失败尝试的次数;
2. 例如,设置 LOG_ARCHIVE_DEST_1在本地归档文件时,如果遇到错误,则每隔100秒尝试一次,共尝试不超过3次,设置如下:LOG_ARCHIVE_DEST_1=’LOCATION=E:/ora10g/oradata/jsspdg/ REOPEN=100 MAX_FAILURE=3′;
5. LOG_ARCHIVE_DEST_STATE_n:是否允许REDO传输服务传输REDO数据到指定的路径:
1. ENABLED:开启传输,默认值;
2. DEFER:阻止传输;
3. ALTERNATE:默认是阻止,当其它路径失败后被激活;
4. RESET:重置;
6. REMOTE_LOGIN_PASSWORDFILE:推荐设置参数值为EXCLUSIVE或者SHARED,注意保证相同Data Guard配置中所有DB服务器SYS密码相同;
2. Standby角色相关的参数(建议在Primary数据库的初始化参数中也进行设置,这样即使发生角色切换,新的Standby也能直接正常运行):
1. FAL_SERVER:指定一个Net服务名,该参数值对应的数据库应为Primary角色.当本地数据库为Standby角色时,如果发现存在归档中断的情况,该参数用来指定获取中断的归档文件的服务器;FAL_SERVER参数支持多个参数值,相互间以逗号分隔;
2. FAL_CLIENT:又指定一个Net服务名,该参数对应数据库应为Standby角色.当本地数据库以Primary角色运行时,向参数值中指定的站点发送中断的归档文件;FAL_CLIENT参数也支持多个参数值,相互间以逗号分隔;
3. DB_FILE_NAME_CONVERT:Standby数据库的数据文件路径与Primary数据库数据文件(包括临时表空间和UNDO表空间)路径不一致时,可以通过设置DB_FILE_NAME_CONVERT参数的方式让其自动转换.该参数值应该成对出现,前面的值表示转换前的形式,后面的值表示转换后的形式;例如:DB_FILE_NAME_CONVERT=‘/path1’,’/path2′;
4. LOG_FILE_NAME_CONVERT:使用方式与上相同,只不过LOG_FILE_NAME_CONVERT专用来转换日志文件路;
5. STANDBY_FILE_MANAGEMENT:Primary数据库数据文件发生修改(如新建,删除等)则按照本参数的设置在Standby数据库中作相应修改.设为AUTO表示自动管理.设为MANUAL表示需要手工管理;
8. 物理Standby和逻辑Standby的区别:
1. 物理Standby:
1. 我们知道物理Standby与Primary数据库完全一模一样,DG通过REDO应用来维护物理Standby数据库;
2. 通常在物理Standby没有执行REDO应用操作的时候,可以将物理Standby数据库以READ ONLY模式打开,如果数据库中指定了Flashback Area的话,甚至还可以被临时性的置为READ WRITE模式,操作完之后再通过Flashback Database特性恢复回READ WRITE前的状态,以便继续接收Primary端发送的REDO并应用;
3. REDO应用:物理Standby通过REDO应用来保持与Primary数据库的一致性,所谓的REDO应用,实质是通过Oracle的恢复机制,应用归档文件(或Standby Redologs文件)中的REDO数据.恢复操作属于块对块的应用.如果正在执行REDO应用的操作,Oracle数据库就不能被Open;
4. READ ONLY模式打开:以READ ONLY模式打开后,可以在Standby数据库执行查询或备份等操作(变相减轻Primary数据库压力).此时Standby数据库仍然能够继续接收Primary数据库发送的REDO数据,不过并不会应用,直到Standby数据库重新恢复REDO应用;
5. 也就是说在READ ONLY模式下不能执行REDO应用,REDO应用时数据库肯定处于未打开状态.如果需要的话,你可以在两种状态间转换,如先应用REDO,然后将数据库置为READ ONLY状态,需要与Primary同步时再次执行 REDO应用命令,切换回REDO应用状态;
6. Oracle 11g版本中增强物理Standby的应用功能,在11g版本中,物理Standby可以在OPEN READ ONLY模式下继续应用REDO数据,这就极大地提升了物理Standby数据库的应用场合;
7. READ WRITE模式打开:如果以READ WRITE模式打开,那么Standby数据库将暂停从Primary数据库接收REDO数据,并且暂时失去灾难保护的功能.当然,以READ WRITE模式打开也并非一无是处,如你可能需要临时调试一些数据,但又不方便在正式库中操作,那就可以临时将Standby数据库置为READ WRITE模式,操作完之后将数据库闪回到操作前的状态(闪回之后,Data Guard会自动同步,不需要重建物理Standby,不过如果从另一个方向看,没有启动闪回,那就回不到READ WRITE前的状态了);
8. 物理Standby特点如下:
1. 灾难恢复及高可用性:物理Standby提供了一个健全,高效的灾难恢复,以及高可用性的解决方案.更加易于管理switchover/failover角色转换及在更短的计划内或计划外停机时间;
2. 数据保护:使用物理Standby数据库,DG能够确保即使面对无法预料的灾害也能够不丢失数据.前面也提到物理Standby是基于块对块的复制,因此与对象,语句无关,Primary数据库上有什么,物理Standby数据库端也会有什么;
3. 分担Primary数据库压力:通过将一些备份任务,仅查询的需求转移到物理Standby数据库,可以有效节省Primary数据库的CPU及I/O资源;
4. 提升性能:物理Standby所使用的REDO应用技术使用最底层的恢复机制,这种机制能够绕过SQL级代码层,因此效率最高;
2. 逻辑Standby
1. 逻辑Standby也要通过Primary数据库(或其备份,或其复制库,如物理Standby)创建,因此在创建之初与物理Standby数据库类似.不过由于逻辑Standby通过SQL应用的方式应用REDO数据, 因此逻辑Standby的物理文件结构,甚至数据的逻辑结构都可以与Primary不一致;
2. 与物理Standby不同,逻辑Standby正常情况下是以READ WRITE模式打开,用户可以在任何时候访问逻辑Standby数据库,就是说逻辑 Standby是在OPEN状态执行SQL应用.同样有利也有弊,由于SQL应用自身特点,逻辑Standby对于某些数据类型及一些DDL/DML语句会有操作上的限制.可以在视图DBA_LOGSTDBY_UNSUPPORTED中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致;
3. 除了上述物理Standby中提到的类似灾难恢复,高可用性及数据保护等特点之外,逻辑Standby还有下列一些特点:
1. 有效地利用备机的硬件资源:除灾难恢复外,逻辑Standby数据库还可用于其他业务需求.如通过在Standby数据库创建额外的索引,物化视图等提高查询性能并满足特定业务需要;又如创建新的SCHEMA(该SCHEMA在Primary数据库端并不存在),然后在这些SCHEMA中执行那些不适于在Primary数据库端执行的DDL或者DML操作等;
2. 分担Primary数据库压力:逻辑Standby数据库可以在保持与Primary同步时仍然置于打开状态,这使得逻辑Standby数据库能够同时用于数据保护和报表操作,从而将主数据库从报表和查询任务中解脱出来,节约宝贵的CPU和I/O资源;
3. 平滑升级:可以通过逻辑Standby来实现如跨版本升级,为数据库打补丁等操作.应该说应用的空间很大,而带来的风险却很小(前提是如果你拥有足够的技术实力.另外虽然物理Standby也能够实现一些升级操作,但如果跨平台的话恐怕就力不从心了,所以此项没有作为物理Standby的特点列出),我个人认为这是一种值得可行的在线的滚动的平滑的升级方式,如果你的应用支持创建逻辑Standby的话;
9. Log应用服务(Log Apply Services)
1. Data Guard通过应用REDO维持Primary数据库与各Standby数据库之间的一致性,在后台默默无闻地支撑着的就是传说中的Log应用服务.Log应用服务又分以下两种方式:
1. REDO应用:物理Standby数据库专用,通过介质恢复的方式保持与Primary数据库的同步;
2. SQL应用:逻辑Standby数据库专用,核心是通过LogMiner分析出SQL语句在Standby端执行;
3. 因此物理Standby在应用REDO数据时必须是MOUNT状态,而逻辑Standby则是以READ WRITE模式打开并应用REDO数据,不过被维护的对象默认处于只读状态,无法在逻辑Standby端直接修改;
2. Log应用服务配置选项:
1. 默认情况下,Log应用服务会等待单个归档文件全部接收之后再启动应用,如果Standby数据库配置了Standby Redologs,就可以打开实时应用(Real-Time Apply),这样Data Guard就不需要再等待接收完归档文件,只要RFS进程将REDO数据写入Standby Redologs,即可通过MRP/LSP实时写向Standby数据库;
2. REDO数据实时应用:
1. 启动实时应用的优势在于,REDO数据不需要等待归档完成,接收到即可被应用,这样执行角色切换时,操作能够执行得更快,因为日志是被即时应用的;
2. 要启动实时应用也简单,前提 Standby数据库端配置了Standby Redologs;
3. 物理Standby要启用实时应用,要在启动REDO应用的语句后附加USING CURRENT LOGFIE子句,例如:SQL>ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE;
4. 逻辑Standby要启用实时应用,只需要在启动REDO应用的语句后附加IMMEDIATE子句即可,例如:SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
3. REDO数据延迟应用:
1. 有实时就有延迟,某些情况下你可能不希望Standby数据库与Primary太过同步,那就可以在Primary数据库端发送REDO数据的相应LOG_ARCHIVE_DEST_n参数中指定DELAY属性(单位为分钟,如果指定了DELAY属性,但没有指定值,则默认是30分钟).(注意:该属性并不是说延迟发送REDO数据到Standby,而是指明归档到Standby后,开始应用的时间;)
2. 例如:设置LOG_ARCHIVE_DEST_3的DELAY属性为15分钟:SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_3=’SERVICE=
3. 如果DBA在启动REDO应用时指定了实时应用,那么即使在LOG_ ARCHIVE_DEST_n参数中指定了DELAY属性,Standby数据库也会忽略DELAY属性;
4. 另外,Standby端还可以在启动REDO应用时,通过附加 NODELAY子句的方式,取消延迟应用;
5. 物理Standby可以通过下列语句取消延迟应用:SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE NODELAY;
6. 逻辑Standby可以通过下列语句取消延迟应用:SQL> ALTER DATABASE START LOGICAL STANDBY APPLY NODELAY;
4. 一般设置延迟应用的需求都是基于容错方面的考虑,如Primary数据库端由于误操作,数据被意外修改或删除,只要Standby数据库尚未应用这些修改,你就可以快速从Standby数据库中恢复这部分数据.不过自Oracle从9i版本开始提供FLASHBACK特性之后,对于误操作使用FLASHBACK特性进行恢复,显然更加方便快捷,因此DELAY方式延迟应用已经非常少见了;
3. 应用REDO数据到Standby数据库:
1. 物理Standby应用REDO数据:
1. 物理Standby启动REDO应用,数据库要处于MOUNT状态;
2. 前台应用:SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE;语句执行完成后,不会将控制权返回到命令行窗口,除非你手动中止应用.在这种情况下如果还需要对数据库进行操作,只能新开一个命令行连接,在Oracle 8i刚推出Standby特性时(那时不叫Data Guard),只提供了这种方式;
3. 后台应用:SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT;这是现在比较通用的方式,语句执行完后,控制权自动返回到当前的命令行模式,REDO应用以后台进程运行.
4. 启动实时应用:附加USING CURRENT LOGFILE子句即可:SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE;
5. 如果要停止REDO应用:执行下列语句即可:SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
2. 逻辑Standby应用REDO数据:
1. SQL应用的原理是将接收到的REDO数据转换成SQL语句在逻辑Standby数据库端执行,因此逻辑Standby需要启动至OPEN状态;
2. 启动SQL应用:逻辑Standby数据库启动SQL应用没有前/后台运行之说,语句执行完之后,控制权就会自动返回当前命令行窗口;
3. 要启动SQL应用:直接执行下列语句即可:SQL> ALTER DATABASE START LOGICAL STANDBY APPLY;
4. 如果要启动实时应用:附加IMMEDIATE子句即可,例如:SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
5. 停止SQL应用:如SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
6. 由于是执行SQL语句的方式应用REDO数据,因此上述语句的执行需要等待当前执行的SQL触发的事务结束,才能真正停止REDO应用的状态;
7. 如果不考虑事务执行情况,马上停止REDO应用,可以通过下列的语句来完成:SQL> ALTER DATABASE ABORT LOGICAL STANDBY APPLY;
Category Archives: Oracle
同一台机器上配置DataGuard
同一台机器上配置DataGuard
1. 实验环境:
1. ip:192.168.10.11;
2. hostname:primary.snda.com;
2. 设置~/.bash_profile,$ORACLE_HOME/network/admin/listener.ora和$ORACLE_HOME/network/admin/tnsnames.ora文件;
3. 创建必要的目录;
4. 修改主库的系统参数,然后关闭数据库,启动到mount状态,并修改数据库为归档模式;
5. 在主库使用spfile创建pfile:CREATE PFILE FROM SPFILE;
6. 备份主库的数据文件和控制文件;
7. 拷贝主库的文件到备库;
8. 修改备库的参数文件;
9. 设置备库的ORACLE_SID,并启动备库到nomount状态;
10. 设置备库的ORACLE_SID, 使用rman恢复备库;
11. 主库备库分别添加Standby Redo Log Fiels;
12. 重启备库,并使用spfile启动到mount状态,并设置应用日志文件;
13. 修改数据库问高可用模式;
14. 切换主库备库的角色;
— ~/.bash_profile文件内容;
ORACLE_SID=PROD
ORACLE_BASE=/u01/app/oracle
ORACLE_HOME=$ORACLE_BASE/product/10.2.0/db_1
PATH=/usr/sbin:$PATH
PATH=$ORACLE_HOME/bin:$PATH
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib
CLASSPATH=$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH LD_LIBRARY_PATH CLASSPATH
alias sqlplus=’rlwrap sqlplus’
alias rman=’rlwrap rman’
alias dgmgrl=’rlwrap dgmgrl’
— $ORACLE_HOME/network/admin/listener.ora文件内容;
LISTENER=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=primary.snda.com)(PORT=1521))
)
)
SID_LIST_LISTENER=
(SID_LIST=
(SID_DESC=
(SID_NAME=PROD)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)
)
(SID_DESC=
(SID_NAME=PRODDG)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)
)
)
— $ORACLE_HOME/network/admin/tnsnames.ora文件内容;
PROD_PRI=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=primary.snda.com)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=PROD)
(SERVER=DEDICATED)
)
)
PROD_SBY=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=primary.snda.com)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=PRODDG)
(SERVER=DEDICATED)
)
)
— 创建必要的目录;
mkdir -p /u01/app/oracle/oradata/PRODDG/
mkdir -p /u01/app/oracle/admin/PRODDG/adump
mkdir -p /u01/app/oracle/admin/PRODDG/bdump
mkdir -p /u01/app/oracle/admin/PRODDG/cdump
mkdir -p /u01/app/oracle/admin/PRODDG/udump
mkdir -p /u01/app/oracle/archivelog/prod
mkdir -p /u01/app/oracle/archivelog/proddg
— 修改主库的系统参数,然后关闭数据库,启动到mount状态,并修改数据库为归档模式;
ALTER SYSTEM SET DB_UNIQUE_NAME=PROD_PRI SCOPE=SPFILE;
ALTER SYSTEM SET LOG_ARCHIVE_CONFIG=’DG_CONFIG=(PROD_PRI,PROD_SBY)’ SCOPE=SPFILE;
ALTER SYSTEM SET LOG_ARCHIVE_DEST_1=’LOCATION=/u01/app/oracle/archivelog/prod VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=PROD_PRI’ SCOPE=SPFILE;
ALTER SYSTEM SET LOG_ARCHIVE_DEST_2=’SERVICE=PROD_SBY LGWR SYNC AFFIRM VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=PROD_SBY’ SCOPE=SPFILE;
ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_1=’ENABLE’ SCOPE=SPFILE;
ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2=’ENABLE’ SCOPE=SPFILE;
ALTER SYSTEM SET REMOTE_LOGIN_PASSWORDFILE=’EXCLUSIVE’ SCOPE=SPFILE;
ALTER SYSTEM SET LOG_ARCHIVE_FORMAT=’%t_%s_%r.arc’ SCOPE=SPFILE;
ALTER SYSTEM SET FAL_SERVER=’PROD_PRI’ SCOPE=SPFILE;
ALTER SYSTEM SET FAL_CLIENT=’PROD_SBY’ SCOPE=SPFILE;
ALTER SYSTEM SET DB_FILE_NAME_CONVERT=’/u01/app/oracle/oradata/PRODDG’,’/u01/app/oracle/oradata/PROD’ SCOPE=SPFILE;
ALTER SYSTEM SET LOG_FILE_NAME_CONVERT=’/u01/app/oracle/oradata/PRODDG’,’/u01/app/oracle/oradata/PROD’ SCOPE=SPFILE;
ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT=’AUTO’ SCOPE=SPFILE;
SHUTDOWN IMMEDIATE;
SHUTDOWN MOUNT;
ALTER DATABASE FORCE LOGGING;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
CREATE PFILE FROM SPFILE;
— 备份主库的数据文件和控制文件;
rman target /
BACKUP DATABASE FORMAT ‘/u01/app/oracle/flash_recovery_area/%U’;
BACKUP CURRENT CONTROLFILE FOR STANDBY FORMAT ‘/u01/app/oracle/flash_recovery_area/%U’;
— 拷贝主库的文件到备库;
cd $ORACLE_HOME/dbs
cp initPROD.ora initPRODDG.ora
orapwd file=orapwPRODDG password=oracle force=y
— 修改备库的参数文件
*.db_name=’PROD’
*.db_block_size=8192
*.db_unique_name=’PROD_SBY’
*.fal_client=’PROD_PRI’
*.fal_server=’PROD_SBY’
*.log_archive_config=’DG_CONFIG=(PROD_PRI,PROD_SBY)’
*.log_archive_dest_1=’LOCATION=/u01/app/oracle/archivelog/proddg VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=PROD_SBY’
*.log_archive_dest_2=’SERVICE=PROD_PRI LGWR SYNC AFFIRM VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=PROD_PRI’
*.log_archive_dest_state_1=’ENABLE’
*.log_archive_dest_state_2=’ENABLE’
*.log_archive_format=’%t_%s_%r.arc’
*.sga_target=300M
*.pga_aggregate_target=150M
*.processes=150
*.compatible=’10.2.0′
*.remote_login_passwordfile=’EXCLUSIVE’
*.standby_file_management=’AUTO’
*.undo_management=’AUTO’
*.undo_tablespace=’UNDOTBS’
*.db_file_name_convert=’/u01/app/oracle/oradata/PROD’,’/u01/app/oracle/oradata/PRODDG’
*.log_file_name_convert=’u01/app/oracle/oradata/PROD’,’/u01/app/oracle/oradata/PRODDG’
*.control_files=’/u01/app/oracle/oradata/PRODDG/control01.ctl’,’/u01/app/oracle/oradata/PRODDG/control02.ctl’
— 设置备库的ORACLE_SID,并启动备库到nomount状态;
ORACLE_SID=PRODDG
sqlplus / as sysdba
STARTUP NOMOUNT
— 设置备库的ORACLE_SID,使用rman恢复备库;
ORACLE_SID=PRODDG
rman target sys/oracle@prod_pri auxiliary /
DUPLICATE TARGET DATABASE FOR STANDBY;
— 分别在主库和备库添加Standby Redo Log files;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 4 (‘/u01/app/oracle/oradata/PROD/redo04.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 5 (‘/u01/app/oracle/oradata/PROD/redo05.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 6 (‘/u01/app/oracle/oradata/PROD/redo06.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 7 (‘/u01/app/oracle/oradata/PROD/redo07.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 4 (‘/u01/app/oracle/oradata/PRODDG/redo04.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 5 (‘/u01/app/oracle/oradata/PRODDG/redo05.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 6 (‘/u01/app/oracle/oradata/PRODDG/redo06.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 7 (‘/u01/app/oracle/oradata/PRODDG/redo07.log’) SIZE 100M;
— 重启备库,并使用spfile启动到mount状态,并设置应用日志文件;
shutdown immediate
CREATE SPFILE FROM PFILE;
startup mount
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT SESSION;
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
— 修改数据库问高可用模式,在主库运行;
ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE AVAILABILITY;
ALTER SYSTEM SWITCH LOGFILE;
— 切换主库备库的角色;
1.在主库运行;
ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY;
shutdown immediate;
startup mount;
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
2.在备库运行;
ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY;
ALTER DATABASE OPEN;
ALTER SYSTEM SWITCH LOGFILE;
SELECT PROTECTION_MODE, PROTECTION_LEVEL, DATABASE_ROLE, SWITCHOVER_STATUS FROM v$database;
DataGuard管理操作命令
1.相关进程:
1.RFS(Remote File Server Process):接收由Primary数据库的lgwr或arch通过Oracle Net传来的redo数据,写入standby redo logs或standby archived redo logs;
2.MRP(Managed Recovery Process):管理恢复进程;
3.FAL(Fetch Archive Log):在Primary和Standby数据库的两端同时配置;Primary端是fetch archive log server,standby端是fetch archive log client,FAL是自动探测Primary/Standby数据库之间archived logs是否有有间隔的一个进程;
2.主备库切换:
1.主库切到备库(SWITCHOVER):
ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY WITH SESSION SHUTDOWN;
STARTUP NOMOUNT;
ALTER DATABASE MOUNT STANDBY DATABASE;
SELECT name, open_mode, protection_mode, database_role, switchover_status from v$DATABASE;
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
2.备库切到主库(SWITCHOVER):
ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY;
STARTUP
SELECT name, open_mode, protection_mode, database_role, switchover_status from v$DATABASE;
3.FAILOVER切换:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE FINISH;
ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY;
ALTER DATABASE OPEN;
SELECT name, open_mode, protection_mode, database_role, switchover_status from v$DATABASE;
3.切换数据库模式:
STARTUP IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE PERFORMANCE/AVAILABILITY/PROTECTION;
ALTER DATABASE OPEN;
4.测试Primary的归档能否应用到Standby:
1.查看v$archive_gap:SELECT * FROM v$archive_gap;
2.ARCHIVE LOG LIST;
5.管理操作:
1.停止Standby:ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;STARTUP IMMEDIATE;
2.切换到只读模式:ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;ALTER DATABASE OPEN READ ONLY;
3.切换到管理恢复模式:ALTER DATABASE RECOVER MANAGED STANDBY DATABASE [PARALLEL 8] [USING CURRENT LOGFILE] DISCONNECT FROM SESSION;
4.查询备机归档日志应用情况:SELECT sequence#, applied FROM v$archived_log;
5.在主库上归档当前日志:ALTER SYSTEM ARCHIVE LOG CURRENT;
6.设置归档频率,强制Primary一分种归档一次:ALTER SYSTEM SET ARCHIVE_LAG_TARGET=60 SCOPE=BOTH;
6.注意事项:
1.如果在主库执行ALTER DATABASE CLEAR UNARCHIVED LOGFILE或ALTER DATABASE OPEN RESETLOGS,则DataGuard要重建;
2.出现归档日志gap时,需要找出相应的归档日志,然后将这些归档日志copy到备用节点的standby_archive_dest和log_archive_dest目录下面;需要注意的是log_archive_dest目录下也需要copy,然后ALTER DATABASE RECOVER AUTOMATIC STANDBY DATABASE;
3.新建表/表空间/datafile都能通过日志应用到备库,但新建一个临时表空间/rename datafile均不能应用到备库上;
4.应当实时察看standby库的alert文件,就能清晰明了地知道主备更新的情况,这也是排错的重要方法;
7.相关视图:
DBA_LOGSTDBY_EVENTS (Logical Standby Databases Only)
DBA_LOGSTDBY_LOG (Logical Standby Databases Only)
DBA_LOGSTDBY_NOT_UNIQUE (Logical Standby Databases Only)
DBA_LOGSTDBY_PARAMETERS (Logical Standby Databases Only)
DBA_LOGSTDBY_PROGRESS (Logical Standby Databases Only)
DBA_LOGSTDBY_SKIP (Logical Standby Databases Only)
DBA_LOGSTDBY_SKIP_TRANSACTION (Logical Standby Databases Only)
DBA_LOGSTDBY_UNSUPPORTED (Logical Standby Databases Only)
V$ARCHIVE_DEST
V$ARCHIVE_DEST_STATUS
V$ARCHIVE_GAP
V$ARCHIVED_LOG
V$DATABASE
V$DATAFILE
V$DATAGUARD_STATUS
V$LOG
V$LOGFILE
V$LOG_HISTORY
V$LOGSTDBY (Logical Standby Databases Only)
V$LOGSTDBY_STATS (Logical Standby Databases Only)
V$MANAGED_STANDBY (Physical Standby Databases Only)
V$STANDBY_LOG
使用RMAN和Broker快速搭建DataGuard环境
使用RMAN和Broker快速搭建DataGuard环境
1. 不适合在生成环境中使用,如果生成环境中搭建dg的话推荐手动配置;
2. 实验环境:
1. 主库:
1. ip:192.168.10.11;
2. hostname:primary.snda.com;
2. 备库:
1. ip:192.168.10.12;
2. hostname:standby.snda.com;
3. 分别设置主库和备库的~/.bash_profile,$ORACLE_HOME/network/admin/listener.ora和$ORACLE_HOME/network/admin/tnsnames.ora文件;
4. 修改主库的系统参数,然后关闭数据库,启动到mount状态,并修改数据库为归档模式,并创建pfile;
5. 备份主库的数据文件和控制文件;
6. 拷贝主库的文件到备库;
7. 修改备库的pfile,创建spfile,并启动到nomount状态;
8. 使用rman恢复备库;
9. 主库备库分别添加Standby Redo Log Fiels;
10. 分别修改主库和备库的初始化参数:dg_broker_start;
11. 在任意一台机器上启动dgmgrl,并配置当前的broker环境;
12. 修改数据库为高可用模式;
13. SWITCHOVER和FAILOVER操作;
14. 切换数据库的状态为只读模式和在线接收日志状态;
— 主库和备库的~/.bash_profile文件内容;
ORACLE_SID=PROD
ORACLE_BASE=/u01/app/oracle
ORACLE_HOME=$ORACLE_BASE/product/10.2.0/db_1
PATH=/usr/sbin:$PATH
PATH=$ORACLE_HOME/bin:$PATH
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib
CLASSPATH=$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH LD_LIBRARY_PATH CLASSPATH
alias sqlplus=’rlwrap sqlplus’
alias rman=’rlwrap rman’
alias dgmgrl=’rlwrap dgmgrl’
— 主库的$ORACLE_HOME/network/admin/listener.ora文件内容,修改完成后运行lsnrctl start/reload重新加载监听文件;
LISTENER=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=primary.snda.com)(PORT=1521))
)
)
SID_LIST_LISTENER=
(SID_LIST=
(SID_DESC=
(SID_NAME=PROD)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)
)
(SID_DESC=
(SID_NAME=PROD)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)
(GLOBAL_DBNAME=PROD_PRI_DGMGRL)
)
)
— 备库的$ORACLE_HOME/network/admin/listener.ora文件内容,修改完成后运行lsnrctl start/reload重新加载监听文件;
LISTENER=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=standby.snda.com)(PORT=1521))
)
)
SID_LIST_LISTENER=
(SID_LIST=
(SID_DESC=
(SID_NAME=PROD)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)
)
(SID_DESC=
(SID_NAME=PROD)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)
(GLOBAL_DBNAME=PROD_SBY_DGMGRL)
)
)
— 主库和备库的$ORACLE_HOME/network/admin/tnsnames.ora文件
PROD_PRI=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=primary.snda.com)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=PROD)
(SERVER=DEDICATED)
)
)
PROD_SBY=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=standby.snda.com)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=PROD)
(SERVER=DEDICATED)
)
)
— 修改主库的系统参数,然后关闭数据库,启动到mount状态,并修改数据库为归档模式,并创建pfile;
ALTER SYSTEM SET db_unique_name=PROD_PRI scope=spfile;
ALTER SYSTEM SET db_recovery_file_dest_size=4G;
ALTER SYSTEM SET db_recovery_file_dest=’/u01/app/oracle/flash_recovery_area’;
ALTER SYSTEM SET log_archive_dest_1=’LOCATION=/u01/app/oracle/flash_recovery_area’;
ALTER SYSTEM SET log_archive_dest_2=”;
ALTER SYSTEM SET local_listener=”;
ALTER SYSTEM SET dispatchers=”;
ALTER SYSTEM SET standby_file_management=AUTO;
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE FORCE LOGGING;
ALTER DATABASE ARCHIVELOG;
— ALTER DATABASE FLASHBACK ON;
ALTER DATABASE OPEN;
CREATE PFILE FROM SPFILE;
— 备份主库的数据文件和控制文件;
rman target /
BACKUP DATABASE FORMAT ‘/u01/app/oracle/flash_recovery_area/%U’;
BACKUP CURRENT CONTROLFILE FOR STANDBY FORMAT ‘/u01/app/oracle/flash_recovery_area/%U’;
— 拷贝主库的文件到备库;
scp /u01/app/oracle/flash_recovery_area/* oracle@standby.snda.com:/u01/app/oracle/flash_recovery_area/
scp $ORACLE_HOME/dbs/initPROD.ora oracle@standby.snda.com:$ORACLE_HOME/dbs/
scp $ORACLE_HOME/dbs/orapwPROD oracle@standby.snda.com:$ORACLE_HOME/dbs/
— 修改备库的pfile,创建spfile,并启动到nomount状态;
修改备库的参数文件,只修改db_unique_name=’PROD_SBY’即可;
CREATE SPFILE FROM PFILE;
STARTUP NOMOUNT;
— 使用rman恢复备库;
rman target sys/oracle@prod_pri auxiliary /
DUPLICATE TARGET DATABASE FOR STANDBY NOFILENAMECHECK;
— 主库备库分别添加Standby Redo Log Fiels;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 4 (‘/u01/app/oracle/oradata/PROD/redo04.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 5 (‘/u01/app/oracle/oradata/PROD/redo05.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 6 (‘/u01/app/oracle/oradata/PROD/redo06.log’) SIZE 100M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 7 (‘/u01/app/oracle/oradata/PROD/redo07.log’) SIZE 100M;
— 分别修改主库备库的初始化参数;
ALTER SYSTEM SET dg_broker_start=TRUE;
— 在任意一台机器上启动dgmgrl,并配置当前的broker环境;
dgmgrl sys/oracle@prod_pri
CREATE CONFIGURATION DGCONFIG1 AS PRIMARY DATABASE IS PROD_PRI CONNECT IDENTIFIER IS PROD_PRI;
ADD DATABASE PROD_SBY AS CONNECT IDENTIFIER IS PROD_SBY MAINTAINED AS PHYSICAL;
ENABLE CONFIGURATION;
SHOW CONFIGURATION;
— 修改数据库为高可用的保护状态;
EDIT DATABASE PROD_PRI SET PROPERTY LogXptMode=’Sync’;
EDIT DATABASE PROD_SBY SET PROPERTY LogXptMode=’Sync’;
EDIT CONFIGURATION SET PROTECTION MODE AS MaxAvailability;
— 切换数据库的主备角色;
SWITCHOVER TO PROD_SBY;
SWITCHOVER TO PRDO_PRI;
SELECT PROTECTION_MODE, PROTECTION_LEVEL, DATABASE_ROLE, SWITCHOVER_STATUS FROM v$database;
— FAILOVER操作;
FAILOVER TO PROD_PRI;
FAILOVER TO PROD_SBY;
— 切换数据库的状态为只读模式和在线接收日志状态;
EDIT DATABASE PROD_SBY SET STATE=’READ-ONLY’;
EDIT DATABASE PROD_SBY SET STATE=’ONLINE’;
— 设置数据库的其它属性;
EDIT DATABASE db SET PROPERTY StandbyFileManagement=’AUTO’;
EDIT DATABASE db SET PROPERTY StandbyArchiveLocation=’/u01/app/oracle/flash_recovery_area’;
— 删除表空间和表空间所有的内容;
DROP TABLESPACE tbs INCLUDE CONTENTS CASCADE CONTRAINTS;
GoldenGate学习7–其它问题
1.truncate操作要单独处理,在EXTRACT和REPLICAT配置文件中添加GETTRUNCATES;
2.主键的解决办法:一个生成奇数,一个生成偶数
Database-generated values
Do not replicate database-generated sequential values in a bi-directional configuration.
The range of values must be different on each system, with no chance of overlap. For
example, in a two-database environment, you can have one server generate even values,
and the other odd. For an n-server environment, start each key at a different value and
increment the values by the number of servers in the environment. This method may not
be available to all types of applications or databases. If the application permits, you can
add a location identifier to the value to enforce uniqueness.
阻止数据循环
1.阻止抽取复制的操作:
1.GETAPPLOPS|IGNOREAPPLOPS
2.GETREPLICATES|IGNOREREPLICATES
2.标识复制的事务:
TRANLOGOPTIONS EXCLUDEUSER
TRANLOGOPTIONS EXCLUDEUSERID
中间主键冲突了怎么办;
主库宕机了,剩余数据是否会同步到备机;
mgr
PURGEOLDEXTRACTS /opt/gg/trails/w1*, USECHECKPOINTS, MINKEEPFILES 10
PURGEOLDEXTRACTS /opt/gg/trails/w2*, USECHECKPOINTS, MINKEEPFILES 10
AUTORESTART ER *, RETRIES 3, WAITMINUTES 5
PURGEDDLHISTORY MINKEEPDAYS 3, MAXKEEPDAYS 5, FREQUENCYMINUTES 30
PURGEMARKERHISTORY MINKEEPDAYS 3, MAXKEEPDAYS 5, FREQUENCYMINUTES 30
init data on soruce
1.add extract eintss, soruceistable
2.edit params eintss
EXTRACT eintss
userid system, password “oracle”
rmthost xxx, mgrport 7809
rmttask replicat, group riniss
table gg.*;
init data on target
3. add replicat riniss, specialrun
info replicat *, tasks;
4.edit params riniss
replicat riniss
assumetargetdefs
userid system, password oracle
discardfile ./dirrpt/RINISS.dsc, purge
map gg.*, target gg.*;
on source
5.start extract einiss;
view report einitss;
6.view report riniss
source 2 target on source
1.ADD EXTRACT ext_s2t, TRANLOG, BEGIN NOW, THREADS 1
EXTRACT ext_s2t
USERID system, PASSWORD oracle
EXTTRAIL ./dirdat/st
DLL INCLUDE MAPPED
TABLE gg.*;
2.ADD EXTTRAIL ./dirdat/st, EXTRACT ext_s2t
3.ADD EXTRACT pump_sr, EXTTRAILSOURCE ./dirdat/st, BEGIN NOW
EXTRACT pump_sr
USERID system, PASSWORD oracle
RMTHOST 192.168.10.12, MGRPORT 7809
RMTTRAIL ./dirdat/tt
PASSTHRU
TABLE gg.*;
4.ADD RMTTRAIL ./dirdat/tt, EXTRACT pump_sr
source 2 target on target
5.ADD REPLICAT repl_tt, EXTTRAIL ./dirdat/tt, BEGIN NOW
REPLICAT repl_tt
ASSUMETARGETDEFS
DLL INCLUDE MAPPED
USERID system, PASSWORD oracle
DISCARDFILE ./dirrpt/repl_tt.dsc, PURGE
MAP gg.*, TARGET gg.*;
————————————————————-
target 2 source on target
1.ADD EXTRACT ext_t2s, TRANLOG, BEGIN NOW, THREADS 1
EXTRACT ext_t2s
USERID system, PASSWORD oracle
EXTTRAIL ./dirdat/ts
DLL INCLUDE MAPPED
TABLE gg.*;
2.ADD EXTTRAIL ./dirdat/ts, EXTRACT ext_t2s
3.ADD EXTRACT pump_tt, EXTTRAILSOURCE ./dirdat/ts, BEGIN NOW
EXTRACT pump_tt
USERID system, PASSWORD oracle
RMTHOST 192.168.10.11, MGRPORT 7809
RMTTRAIL ./dirdat/ss
PASSTHRU
TABLE gg.*;
4.ADD RMTTRAIL ./dirdat/ss, EXTRACT pump_tt
target 2 source on srouce
5.ADD REPLICAT repl_ss, EXTTRAIL ./dirdat/ss, BEGIN NOW
REPLICAT repl_ss
ASSUMETARGETDEFS
DLL INCLUDE MAPPED
USERID system, PASSWORD oracle
DISCARDFILE ./dirrpt/repl_ss.dsc, PURGE
MAP gg.*, TARGET gg.*;
冲突的现象
1.插入时主键冲突
2.更新/删除冲突
解决的办法:
1.读写分离
2.设置很小的延迟,A操作的更改在B操作的更改完成之前反应到B的话就避免了冲突;
使用gg的CDR(Conflict Detection and Resolution)特性
1.解决插入时主键冲突
2.更新/删除时找不到数据;
约束:数据库必须在同类的OS平台上,只支持可以比较而且是没有显式转换的数据类型
GoldenGate学习6–Oracle到SQLServer数据同步
1.相关环境;
Oracle:11.2.0.1 on Linux x64
SQLServer:2005 on Windows 2008R2 x64
OGG:12.1.2.1.0
2.准备源端(Oralce端);
2.1开启数据库级别附加日志;
SELECT supplemental_log_data_min, force_logging FROM v$database;
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
SQL> ALTER DATABASE FORCE LOGGING;
SELECT supplemental_log_data_min, force_logging FROM v$database;
SQL> ALTER SYSTEM SWITCH LOGFILE;
2.2创建用户并授权;
CREATE USER ggadm IDENTIFIED BY ‘********’;
EXEC dbms_goldengate_auth.grant_admin_privilege(‘ggadm’); for Oracle 11.2.0.4 and later
EXEC dbms_goldengate_auth.grant_admin_privilege(‘ggadm’,grant_select_privileges=>true); for Oracle 11.2.0.3 or Earlier
2.3开启相关参数;
ALTER SYSTEM SET ENABLE_GOLDENGATE_REPLICATION=true; for an Oracle 11.2.0.4 or greated database
2.4在ogg中配置安全认证;
./ggsci
ADD CREDENTIALSTORE
ALTER CREDENTIALSTORE ADD USER ggadm, PASSWORD ******** ALIAS alias ogg
2.5开启表级别附加日志(可选);
./ggsci
DBLOGIN USERIDALIAS ogg
ADD TRANDATA [container.]schema.table
INFO TRANDATA [container.]schema.table
3.配置表结构映射;
3.1在源端定义需要映射的表;
./ggsci
EDIT PARAM DEFGEN
DEFSFILE ./dirdef/source.def, PURGE
USERIDALIAS alias
TABLE schema.table1;
TABLE schema.table1;
3.2生成映射文件;
shell> defgen paramfile ./dirprm/defgen.prm
3.3拷贝文件到目标端相应的目录;
4.在源端和目标端分别开启管理进程;
EDIT PARAMS mgr
PORT 7809
START mgr
INFO mgr
5.在源端配置数据泵抽取(Data Pump Extract)进程;
ADD EXTRACT EXT1, TRANLOG, BEGIN NOW, THREADS 1
EDIT PARAMS ext1
EXTRACT ext1
USERIDALIAS ogg
RMTHOST dst_ip, MGRPORT 7809 ENCRYPT AES192, KEYNAME securekey2
RMTTRAIL ./dirdat/rt
# SEQUENCE schema.sequence_name;
TABLE schema.table;
ADD RMTTRAIL ./dirdat/rt, EXTRACT ext1, MEGABYTES 100;
INFO RMTTRAIL *
# START EXTRACT ext1
# INFO EXTRACT ext1, DETAIL
6.配置目标端(SQLServer端);
6.1配置ODBC数据源:控制面板->管理工具->数据源(ODBC)->系统DSN(添加),择驱动程序类型为[SQL Server Native Client],比如:名字为ogg;
6.2在目标端创建一样的表结构;
6.3添加检查点表;
./ggsci
EDIT PARAMS ./GLOBALS
CHECKPOINTTABLE ggschkpt
DBLOGIN SOURCEDB ogg, USERID uid, PASSWORD pwd
ADD CHECKPOINTTABLE
退出之后再进一次客户端;
6.4在目标端配置复制(Change Delivery)进程;
ADD REPLICAT rpl1, EXTTRAIL E:\ogg121\dirdat\rt
EDIT PARAMS rpl1
REPLICAT rpl1
TARGETDB ogg, USERID uid, PASSWORD pwd
HANDLECOLLISIONS
SOURCEDEFS E:\ogg121\dirdef\source.def
REPERROR DEFAULT, DISCARD
DISCARDFILE E:\ggate\dirrpt\rpl1.dsc APPEND
GETTRUNCATES
MAP schema.table, TARGET db.table;
# START REPLICAT rpl1
# INFO REPLICAT rpl1
7.查看对应的报告;
7.1查看抽取进程报告;
SEND EXTRACT EXT1, REPORT
VIEW REPORT EXT1
7.2查看复制进程报告;
SEND REPLICAT RPL1, REPORT
VIEW REPORT RPL1
TIPS:在Windows下安装ogg时需要注册服务;
C:\GG_DIR> INSTALL ADDSERVICE
./ggsci
CREATE SUBDIRS
GoldenGate学习5–Oracle to MySQL
GoldenGate for Oracle to MySQL
1. Environments;
1. Source Database:
1. Oracle:11g R2;
2. Ip Address:192.168.10.11;
3. Hostname:primary.snda.com;
4. Oracle SID:primary;
2. Target Database:
1. Mysql:5.5.21;
2. Ip Address:192.168.10.55;
3. Hostname:master.snda.com;
2. Oracle to Mysql configuration;
3. Prepare the Environment;
1. Description:
1. The GoldenGate software must be installed on both the source and target systems;
2. The installation includes a sample database and scripts to generate initial data as well as subsequent update operations;
3. The source and target tables are created and loaded with initial data;
4. the GoldenGate Manager processes are also started so that other processes may be configured and started;
2. Prepare the Oracle source environment:
1. 在源数据库创建gg用户,并赋予一定的权限:create user gg identified by gg default tablespace example;grant connect, resource to gg;(一定要保证表/表空间是logging的,select table_name, tablespace_name, logging, owner from dba_tables where owner=’GG’;)
2. 在源数据库的gg用户下创建测试使用的表(脚本是GoldenGate安装目录下的demo_ora_create.sql文件);
3. 在源数据库的测试表中添加测试数据(脚本是GoldenGate目录下的demo_ora_insert.sql文件);
4. Add supplemental logging;
5. Configure the Manager process on the source;
3. Prepare the Mysql target environment:
1. 准备数据;
2. Configure the Manager process;
3. create a user;
4. Configure Initial Data Load using Direct Load;
1. Initial Load Methods:
1. Oracle GoldenGate Methods;
2. Database-specific Methods:
1. Backup/Restore;
2. Export/Import;
3. SQL scripts;
4. Break mirror;
5. Transportable tablespaces;
6. Note:
1. Run a test initial load early on for timing and sizing;
2. Run the actual initial load after starting change capture on the source;
3. Current use;
2. Initial data capture on source:
1. add the initial load capture batch task group:GGSCI> add extract eint
2. configure the initial load capture parameter file:GGSCI> edit params eint
3. Initial data delivery on target:
1. add the initial load delivery batch task:GGSCI>add replicat rini
2. configure the initial load delivery parameter file;(assumetargetdefs:假定目标数据库和源数据库表结构一致;discardfile:失败的记录记录的文件;)
4. Define the source.def:
1. 定义defgen参数文件;
2. 执行定义参数文件:dengen paramfile ./dirprm/defgen.prm,会生成表结构定义文件./dirdef/source.def;
3. 拷贝到目标数据库相应的目录下;
5. Execute the initial load process:
1. start extract process:start extract eini
2. view the results on the target system:view report rini
3. 在目标数据库中查看数据;
5. Configure Change Capture(online mode);
1. Extract can be configured to:
1. Capture changed data from database logs;
2. Capture data directly from source tables for initial data load;
3. Write the data to a local or remote trail or file;
2. add the extract group:add extract emsq
3. create the extract parameter file;
4. define the GoldenGate trail:add rmttrail ./dirdat/
5. start the capture process:start extract eora
6. 可以通过view report eorasd查看日志;
6. Configure Change Delivery;
1. set up the checkpoint table;
1. create a GLOBALS file on the target system;(exit and save)
2. activate the GLOBALS parameters;
2. Configure Change Delivery;
1. add the replicat group;
2. create replicat parameter file;
3. start the replicat process;
7. Generate Activity and Verify the Results;
1. exceute miscellaneous update, insert and delete operations on source system;
2. verify results on the source system;
3. verify results on the target system;
4. turn off error handling;
8. Parameter Files Knowlege:
1. Editing Parameter Files:
1. Edit parameter files to configure GoldenGate processes;
2. The GLOBALS parameter file is identified by its file path:GGSCI>edit params ./GLOBALS;
3. Manager and utility parameter files are identified by keywords:GGSCI>edit params mgr/defgen;
4. Extract and Replicat parameter files are identified by the process groiup name:GGSCI>edit params
2. GLOBALS Versus Process Parameters:
1. GLOBALS parameter apply to all processes:
1. set when Manager starts;
2. reside in
2. Process parameters apply to a specific process(Manager, Extract, Server Collector, Replicat, Utilities):
1. set when the process starts;
2. override GOLBALS settings;
3. reside by defaults in the dirprm directory in files named
4. most apply to all tables processed but some can be specified at the table level;
3.
GLOBALS Parameters:
1. Control things common to all processes in a GoldenGate instance;
2. Can be overridden by parameters at the process level;
3. Must be created before any processes are started;
4. Must exit GGSCI to save;
5. Once set, rarely changed;
6. MGRSERVNAME:defines a unique Manager service name;
7. CHECKPOINTTABLE:Defines the table name used for Replicat’s checkpoint table;
GoldenGate学习4–Oracle to Oracle workshop demonstration
GoldenGate for Oracle to Oracle
1. Environments;
1. Source Database:
1. Oracle:11g R2;
2. Ip Address:192.168.10.11;
3. Hostname:ggsource.snda.com;
4. Oracle SID:ggsource;
2. Target Database:
1. Oracle:11g R2;
2. Ip Address:192.168.10.12;
3. Hostname:ggtarget.snda.com;
4. Oracle SID:ggtarget.snda.com;
2. Oracle to Oracle configuration;
3. Prepare the Environment;
1. Description:
1. The GoldenGate software must be installed on both the source and target systems;
2. The installation includes a sample database and scripts to generate initial data as well as subsequent update operations;
3. The source and target tables are created and loaded with initial data;
4. the GoldenGate Manager processes are also started so that other processes may be configured and started;
2. 准备测试数据:
1. 分别在源数据库和目标数据库创建gg用户,并赋予一定的权限:create user gg identified by gg default tablespace example;grant connect, resource to gg;(一定要保证表是logging的,select table_name, tablespace_name, logging, owner from dba_tables where owner=’GG’;)
2. 分别在源数据库和目标数据库的gg用户下创建测试使用的表(脚本是GoldenGate安装目录下的demo_ora_create.sql文件);
3. 只在源数据库的测试表中添加测试数据(脚本是GoldenGate目录下的demo_ora_insert.sql文件);
3. Configure the Manager process on the source and target:
1. Create the Manager parameter file;
2. Use edit to assign a port(7809 default),其实是编辑了/gg11/dirprm/mgr.prm文件;
3. Start the Manager and View the Manager process;
4. 查看后台进程验证:ps -ef | grep mgr;
5. 可以通过直接打开日志文件(/gg11/dirrpt/MGR.rpt文件)或者使用view report mgr命令查看Manager的日志;
4. Supplemental Logging:
1. Add database level supplmental logging on source and target:done when GoldenGate installed;
2. Add table level supplemental logging on srouce and target;
3. Verify that supplemental logging infos;
4. Configure Initial Data Load;
1. Initial Load Methods:
1. Oracle GoldenGate Methods;
2. Database-specific Methods:
1. Backup/Restore;
2. Export/Import;
3. SQL scripts;
4. Break mirror;
5. Transportable tablespaces;
6. Note:
1. Run a test initial load early on for timing and sizing;
2. Run the actual initial load after starting change capture on the source;
3. Current use;
2. Initial data capture:
1. add the initial load capture batch task group:GGSCI> add extract eint
2. configure the initial load capture parameter file:GGSCI> edit params eint
3. Initial data delivery:
1. add the initial load delivery batch task:GGSCI>add replicat rini
2. configure the initial load delivery parameter file;(assumetargetdefs:假定目标数据库和源数据库表结构一致;discardfile:失败的记录记录的文件;)
4. Execute the initial load process:
1. start extract process:start extract eint
2. view the results on the target system:view report rini
3. 在目标数据库中查看数据;
5. Configure Change Capture(online mode);
1. Extract can be configured to:
1. Capture changed data from database logs;
2. Capture data directly from source tables for initial data load;
3. Write the data to a local or remote trail or file;
2. add the extract group:add extract eora
3. create the extract parameter file;
4. define the GoldenGate trail:add rmttrail ./dirdat/
5. start the capture process:start extract eora
6. 可以通过view report eorasd查看日志;
6. Configure Change Delivery;
1. set up the checkpoint table;
1. create a GLOBALS file on the target system;(exit and save)
2. activate the GLOBALS parameters;
2. Configure Change Delivery;
1. add the replicat group;
2. create replicat parameter file;
3. start the replicat process;
7. Generate Activity and Verify the Results;
1. exceute miscellaneous update, insert and delete operations on source system;
2. verify results on the source system;
3. verify results on the target system;
4. turn off error handling;
8. Parameter Files Knowlege:
1. Editing Parameter Files:
1. Edit parameter files to configure GoldenGate processes;
2. The GLOBALS parameter file is identified by its file path:GGSCI>edit params ./GLOBALS;
3. Manager and utility parameter files are identified by keywords:GGSCI>edit params mgr/defgen;
4. Extract and Replicat parameter files are identified by the process groiup name:GGSCI>edit params
2. GLOBALS Versus Process Parameters:
1. GLOBALS parameter apply to all processes:
1. set when Manager starts;
2. reside in
2. Process parameters apply to a specific process(Manager, Extract, Server Collector, Replicat, Utilities):
1. set when the process starts;
2. override GOLBALS settings;
3. reside by defaults in the dirprm directory in files named
4. most apply to all tables processed but some can be specified at the table level;
3.
GLOBALS Parameters:
1. Control things common to all processes in a GoldenGate instance;
2. Can be overridden by parameters at the process level;
3. Must be created before any processes are started;
4. Must exit GGSCI to save;
5. Once set, rarely changed;
6. MGRSERVNAME:defines a unique Manager service name;
7. CHECKPOINTTABLE:Defines the table name used for Replicat’s checkpoint table;
GoldenGate学习3–Install Oracle GoldenGate on Linux
Oracle GoldenGate for Linux Installation
1. Objectives
1. Download an Oracle GoldenGate Media Pack;
2. Install Oracle GoldenGate on Linux, Unix and Windows;
3. Locate and use Oracle GoldenGate documentation;
4. Use the Oracle GoldenGate command interface;
2. Installation Steps:
1. Downloading Oracle GoldenGate software;
1. GoldenGate是属于Oracle的中间件,可以到www.oracle.com->Downloads菜单->Middleware下选择GoldenGate及帮助文档下载(http://www.oracle.com/technetwork/middleware/goldengate/downloads/index.html);
2. 也可以到http://edelivery.oracle.com登陆后下载;
3. 选择Media Pack:Oracle Fusion Middleware and Platform:Linux x86;
4. 选择GoldenGate软件,并选择合适的版本;
5. 如果是其他数据库(mysql,mssql,db2),应该选择;
2. Preparing the Oracle GoldenGate software;
1. 把下载的文件上传到服务器,然后解压缩:unzip ogg112101_fbo_ggs_Linux_x86_ora11g_32bit.zip;
2. 创建GoldenGate的目录/gg11,然后把tar包解到/gg11目录下:tar xvf /tools/fbo_ggs_Linux_x86_ora11g_32bit.tar -C /gg11/;
3. 为了避免权限的问题,把/gg11目录修改为oracle:oinstall用户和组,oracle用户安装oracle软件也安装GoldenGate软件:chown -R oracle:oinstall /gg11/;
3. Setting ORACLE_HOME and ORACLE_SID:安装oracle时已经设置;
4. Setting library paths for dynamic builds;
5. Installing the Oracle GoldenGate software;
1. 进入到GoldenGate软件的目录/gg11/并执行ggsci命令;
2. 执行CREATE SUBDIRS命令安装;
3. 安装完成,查看生成的目录:ll -ltr /gg11/;
6. Oracle-specific installation steps;
1. View the supplemental logging at the database level;
2. Turn on supplemental logging at the database level(把一些附加信息添加到redo log中,默认redo log只记录rowid,因为两台机器的rowid是不同的,所以要添加附加信息);
3. Switch to the next redo log file;
3. Introduce GoldenGate Directories
1. dirchk:GoldenGate checkpoint files;
2. dirdat:GoldenGate trail and extract files;
3. dirdef:Data definitions produced by DEFGEN and used to translate heterogeneous data;
4. dirpcs:Process status files;
5. dirprm:Parameter files;
6. dirrpt:Process report files;
7. dirsql:SQL scripts;
8. dirtmp:Temporary storage for transactions that exceed allocated memory;
4. Oracle GoldenGate Important Documentation;
1. Administration Guide;
2. Reference Guide;
3. Troubleshooting and Tuning Guide;
5. Command Interface-Starting and Help,命令行下如何使用帮助;
1. 进入GoldenGate目录,运行ggsci命令,此时目录下的help.txt文件才会被加载进来,使用help 或者help all命令;
2. 查看具体某条命令的帮助使用:help
GoldenGate学习2–Oracle GoldenGate technical architecture
Oracle GoldenGate Technical Architecture
1. Objectives:
1. Describe Oracle GoldenGate uses;
2. Lean the components of Oracle GoldenGate;
3. Explain change capture and delivery(with and without a dump);
4. Explain inital data load;
5. Contrast batch and online operation;
6. Explain Oracle GoldenGate checkpointing;
7. Describe Oracle GoldenGate parameters, process groups and GGSCI commands;
2. Oracle GoldenGate Users:
1. Primarily userd for change data capture and delivery from database transaction logs;
2. Can optionally be used for initial load directly from database tables:
1. Especially usefull for synchronizing heterogeneous databases,对异构数据库之间同步数据特别有用;
2. Database-specific methods may be preferable for homogeneous configurations,同构数据库之间最好使用数据库本身的方法;
3. Oracle GlodenGate Components:
1. Extract:process,source;
2. Data Pump:process,source;
3. Replicat:process,target;
4. Trails or Extract files:file,source and target;
5. Checkpoints:process;
6. Manager:process,source and target;
7. Collector:process,target;
4. 使用中的各种场景:
1. Change Data Capture and Delivery;
2. Change Data Capture and Delivery using a Data Pump;
3. Bidirectional Configuration;
4. Initial Load;
5. Abount the trails:
1. To support the continuous extraction and replication of database changes, Oracle GoldenGate stores the captured changes temporarily on disk in a series of files called a trail;
2. A trail can exist on the source or target system, or an intermediary system, depending on your configuration;
3. On the local system it’s know as an extract trail(or local trail), On a remote system it’s known as a remote trail;
4. All files names in a trail begin with the same two characters which you assign when you create the trail(max 10m default). As files are created, each name is appended with a unique, six-digit serial number from 000000 through 999999, for example:/gg11/dirdat/tr000018;
6. Data Pump:In most business cases, you should use a data pump, some reasons for using a data pump include the followint;
1. Protection against network and target failures;
2. Implementing serveral phases of data filtering or transformation;
3. Consolidating data from many sources to a central target;
4. Synchronizing one source with multiple targets;
7. Procesing Methods:
1. Oracle GoldenGate can be configured for the following purposes:
1. A static extraction of selected data records from one database and loading of those records to another database;
2. Online or batch extraction and replication of selected transactional data changes and DDL changes(for supported database) to keep source and target data consistent;
3. Extraction from database and replication to a file outside the database;
2. Methods:
1. An online process runs until stopped by a user, you can use online processes to continuously extract and replicate transactional changes and DDL changes(where supported);
2. A bach run, or special run, process extracts or replicates database changes that were generated within know begin and end points;
3. A task is a special type of batch run process and is used for certain initial load methods. A task is a configuration in which Extract communicates directly with Replicat over TCP/OP. Neither a Collector process nor temporary disk storage in a trail or file is used;
8. Checkpointing:Capture, Pump, and Delivery save positions to a checkpoint file so they can recover in case of failure;
9. Parameters, Process Groups and Commands:
1. GoldenGate processes are configured by ASCII parameter files;
2. A process group consists of:
1. An Extract or Replicat process;
2. Associated parameter file;
3. Associated checkpoint file;
4. Any other files associated with that process;
5. Each process group on a system must have a unique group name;
3. Processes are added and started using the GoldenGate Software Command Interface(GGSCI) with the group name;
4. GGSCI commands also add trails, check process status,etc;
GoldenGate学习1–Oracle GoldenGate Overview
Oracle GoldenGate Overview
1. Oracle GoldenGate software enable real-time, continuous movement of transactional data across operational and analytical business systems;
2. Real-Time Acccess to Real-Time Information
1. Real-Time Access:availability,the degree to which information can be instantly accessed;
2. Real-Time Information:integration,the process of combining data from different sources to provide a unified view;
3. Transactional Data Management
1. Oracle GoldenGate provides low-impact capture, routing, transformation, and delivery of database transactions across heterogeneous environments in real time;
2. Key Capabilities:
1. Real Time:moves with sub-second latency;
2. Heterogeneous:moves changed data across different databases and platforms;
3. Transactional:maintains transaction integrity;
3. Additoinal Differentiators:
1. Performance:log-based capture moves thousands of transactions per second with low impact;
2. Extensibility and Flexibility:meets variety of customer needs and data environments with open, modular architecture;
3. Relibility:resilient against interrputions and failures;
4. Technical Architecture Overview;
5. Oracle GoldenGate Topologies;
6. Oracle GoldenGate Solutions:
1. High Availability and Disaster Torlerance:
1. Live Standby;
2. Active-Active;
3. Zero-Downtime Operations for upgrades, migrations, Maintenance;
2. Real-Time Data Integration:
1. Real-time Data warehousing;
2. Live Reporting;
3. Transactional Data Integration;
3. Oracle GoldenGate Solutions Overview;
7. Oracle GoldenGate:Databases and Platforms
1. O/S and Platforms:
1. Windows 2000, 2003, xp;
2. Linux;
3. Sun Solaris;
4. HP NonStop;
5. HP-UX;
6. HP TRU64;
7. HP OpenVMS;
8. IBM AIX;
9. IBM z/OS;
2. Databases:
1. Capture:
1. Oracle;
2. Mysql;
3. IBM DB2;
4. MSSQL;
5. Sybase ASE;
6. Ingres;
7. Teradata;
8. Enscribe;
9. SQL/MP;
10. SQL/MX;
2. Delivery:
1. all listed above;
2. HP Neoview, Netezza and any ODBC compatible databases;
3. ETL products;
4. JMS message queues or topics;
8. Oracle GoldenGate and Oracle Active Data Guard;
1. For information distribution and consolidation, application upgrades and changes:use goldengate-heterogeneous,active-active,transformations,subsetting;
2. for disaster recovery/data protection/ha:
1. simple full oracle database protection:use active data guard;
2. applicatoin desiring flexible ha,active-active,schema change,platform changes:use oracle goldengate;
3. combine the two for full database protection and information distribution;
9. Oracle GoldenGate Advantages;
10. Oracle GoldenGate Director(gg的图形化管理界面)
1. Manages,defines,configures,and reports on Oracle GoldenGate components;
2. Key features:
1. Centralized management of Oracle GoldenGate modules;
2. Rich-client and Web-based inferfaces;
3. Alert notifications and integration with 3rd-party monitoring products;
4. Real-time feedback;
5. Zero-impact implementation;
3. A graphical enterprise application that offers a visual and intuitive way to define,configure,manage,and report on all GoldenGate transactional data synchronization processes;
4. Prerequisites:
1. oracle weblogic server 11g standard,includes a JDBC driver needed for the Diector repository and appropriate version of JRE;
2. the Director Server repository requires databses:oracle or mysql 5.x;
3. Director installer requires a windows system and Unix or Linux systems;
11. Oracle GoldenGate Veridata(数据比较工具);
1. A high-speed,low impact data comparison solution:
1. identifies and reports data discrepancies between two database without interrupting those systems or the business processes they support;
2. supports Oracle, Teradata, MSSQL, NonStop, SQL/MP and Enscribe;
3. Support homogeneous and heterogeneous compares;
2. Benefits:
1. Reduce financial/legal risk exposure;
2. Speed and simplify IT work in comparing data sources;
3. No disruption to business systems;
4. Imporved failover to backup systems;
5. Confident decision-making and reporting;
12. Oracle GoldenGate products
1. Oracle GoldenGate:Includes GoldenGate Capture,Deliver and Active Data Guard and XSystem;
2. Oracle GoldenGate for Mainframe:Includes GoldenGate Capture and Deliver for HP NonStop and IMB DB2 on z/OS;
3. Oracle GoldenGate Veridata:Add-on capability to validate data in replicated systems;
4. Management Pack for GoldenGate:Add-on management pack,includes Oracle GoldenGate Director;
5. Oracle GoldenGate Adapters:Pre-packaged application content,such as for Flat File and Java adapters;
13. GodelGate and Streams
1. GoldenGate is Oracle’s strategic replicatoin solution;
2. Streams continues to be a supported Oracle Databases feature;
3. Best Stream technology will be integrated into GoldenGate;
mysqldump Error 3024: Query execution was interrupted
mysqldump时可能出现的一个error,完整报错如下:
mysqldump: Error: Query execution was interrupted, maximum statement execution time exceeded when trying to dump tablespaces
mysqldump: Error 3024: Query execution was interrupted, maximum statement execution time exceeded when dumping table `$tb_name` at row: 25002
在SELECT时也有可能报该错:
ERROR 3024 (HY000): Query execution was interrupted, maximum statement execution time exceeded
该问题仅发生在5.7.8+的版本
原因是max_execution_time设置过小导致。
将max_execution_time设置成很小的值,执行mysqldump(本质也是执行SELECT)或者SELECT语句即可复现:
- [17:23:01] root@localhost [(none)]> SET GLOBAL max_execution_time=10;
- Query OK, 0 rows affected (0.00 sec)
- [17:23:11] root@localhost [(none)]> SELECT * FROM test.t1 LIMIT 100000;
- ERROR 3024 (HY000): Query execution was interrupted, maximum statement execution time exceeded
- mysqldump -uxxx -pxxx -S xxx.socket -A > /tmp/a.sql
- mysqldump: Error 3024: Query execution was interrupted, maximum statement execution time exceeded when dumping table `$tb_name` at row: 0
可以考虑以下解决方案:
① 通过hints,设置一个较大的N值。
SELECT /*+ MAX_EXECUTION_TIME(N) */ * FROM t1 LIMIT 100000;
② 修改max_execution_time值,将该值设置为较大一个值,或设置为0(不限制)。
相关参数:
max_execution_time
该参数5.7.8被添加,单位为ms,动态参数,默认为0。
设置为0时意味着SELECT超时不被设置(不限制超时时间)。
不作用于存储过程中的SELECT语句,并且只作用于只读的SELECT,比如INSERT … SELECT … 是不被作用的。
在VirtualBox中安装Oracle 12c RAC
1.实验环境:
1.OS:Oracle Linux Server release 6.6;
2.Oracle:12.1.0.2.0;
3.Node1:
1.hostname:node1.oracle.com;
2.public ip:192.168.10.170(eth0);
3.private ip:191.168.20.170(eth1);
4.virtual ip:192.168.10.173;
4.Node2:
1.hostname:node2.oracle.com;
2.public ip:192.168.10.171(eth0);
3.private ip:191.168.20.171(eth1);
4.virtual ip:192.168.10.174;
5.SCAN IP:192.168.10.177/192.168.10.178/192.168.10.179;
2.配置网络环境,安装软件包并调整服务器的时间和参数:
1.设置服务器名:hostname;
2.修改/etc/hosts,/etc/sysconfig/network;
3.使用ntp服务器保持时间同步;
4.设置IP地址;
5.配置DNS服务器,并修改/etc/resolv.conf配置文件;
6.安装软件包:yum -y install binutils* compat-lib* gcc* glibc* ksh make* sysstat* unixODBC* libgcc* libstdc++* libaio* libXext* libXtst* libX11* libXau* libxcb* libXi*;
7.分别修改/etc/sysctl.conf文件;
8.分别修改/etc/security/limits.conf文件;
9.修改/etc/pam.d/login文件;
10.创建grid和oracle用户及添加相应的环境变量;
11.关闭防火墙和SELinux;
3.使用udev创建共享磁盘;
4.安装GI;
1.解压软件;
2.安装cvu相关rpm包:rpm -ivh /tools/grid/rpm/cvuqdisk-1.0.9-1.rpm;
3.安装前校验:/tools/grid/runcluvfy.sh stage -pre crsinst -n node1,node2 -verbose;
4.最后检查资源状态:crsctl stat res -t;
5.使用asmca命令创建磁盘组;
1.创建GI的时候已经创建了CRS磁盘组;
2.创建DATA磁盘组;
3.创建FRA磁盘组;
6.安装数据库软件;
7.安装数据库;
1.查看资源状态:crsctl stat res -t;
2.查看RAC数据库配置信息:srvctl config database -d ORCL/srvctl status database -d ORCL/srvctl status listener;
———————– 网络配置 ———————–
— 修改主机名;
hostname node1.oracle.com
hostname node2.oracle.com
— 修改/etc/hosts;
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# Public IP
192.168.10.170 node1.oracle.com node1
192.168.10.171 node2.oracle.com node2
# Private IP
192.168.20.170 node1-pri.oracle.com node1-pri
192.168.20.171 node2-pri.oracle.com node2-pri
# VIP
192.168.10.172 node1-vip.oracle.com node1-vip
192.168.10.173 node2-vip.oracle.com node2-vip
# Scan IP
192.168.10.177 rac-cluster-scan.oracle.com rac-cluster-scan
#192.168.10.178 rac-cluster-scan.oracle.com rac-cluster-scan
#192.168.10.179 rac-cluster-scan.oracle.com rac-cluster-scan
# DNS Server
#192.168.10.180 rac-dns.oracle.com rac-dns
— 修改/etc/sysconfig/network;
HOSTNAME=node1.oracle.com
HOSTNAME=node2.oracle.com
———————– 网络配置 ———————–
———————– 系统参数 ———————–
— 修改/etc/sysctl.conf文件;
fs.file-max = 6815744
kernel.sem = 250 32000 100 128
kernel.shmmni = 4096
kernel.shmall = 1073741824
kernel.shmmax = 4398046511104
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
fs.aio-max-nr = 1048576
net.ipv4.ip_local_port_range = 9000 65500
> sysctl -p;
— 修改/etc/security/limits.conf文件;
grid soft nproc 2047
grid hard nproc 16384
grid soft nofile 4096
grid hard nofile 65536
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 4096
oracle hard nofile 65536
— 修改/etc/pam.d/login文件;
session required /lib/security/pam_limits.so
session required pam_limits.so
———————– 系统参数 ———————–
———————– 创建用户 ———————–
— 创建用户组;
groupadd -g 10001 oinstall
groupadd -g 10002 dba
groupadd -g 10003 oper
groupadd -g 10004 backupdba
groupadd -g 10005 dgdba
groupadd -g 10006 kmdba
groupadd -g 10007 asmdba
groupadd -g 10008 asmoper
groupadd -g 10009 asmadmin
— 创建用户;
useradd -u 10000 -g oinstall -G dba,oper,asmdba,backupdba,dgdba,kmdba oracle;
useradd -u 10001 -g oinstall -G dba,asmdba,asmoper,asmadmin grid;
— 创建软件目录;
mkdir -p /u01/app/grid;
mkdir -p /u01/app/12.1.0/grid;
mkdir -p /u01/app/oracle/product/12.1.0/db_1;
chown -R grid:oinstall /u01;
chown -R oracle:oinstall /u01/app/oracle;
chmod -R 775 /u01;
— 设置grid用户的环境变量.bash_profile
ORACLE_HOSTNAME=node1.oracle.com
ORACLE_SID=+ASM1
ORACLE_BASE=/u01/app/grid
ORACLE_HOME=/u01/app/12.1.0/grid
PATH=$ORACLE_HOME/bin:/usr/sbin:$PATH
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib:/lib
CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
export ORACLE_HOSTNAME ORACLE_SID ORACLE_BASE ORACLE_HOME PATH LD_LIBRARY_PATH CLASSPATH
alias sqlplus=’rlwrap sqlplus’
— 设置oracle用户的环境变量.bash_profile
ORACLE_HOSTNAME=node1.oracle.com
ORACLE_SID=ORCL1
ORACLE_UNQNAME=ORCL
ORACLE_BASE=/u01/app/oracle
ORACLE_HOME=$ORACLE_BASE/product/12.1.0/db_1
PATH=$ORACLE_HOME/bin:/usr/sbin:$PATH
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib
CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
export ORACLE_HOSTNAME ORACLE_SID ORACLE_UNQNAME ORACLE_BASE ORACLE_HOME PATH LD_LIBRARY_PATH CLASSPATH
alias sqlplus=’rlwrap sqlplus’
———————– 创建用户 ———————–
———————– 创建共享磁盘 ———————–
— 在一个虚拟机中创建[固定大小]的虚拟磁盘;
— 然后在[管理]->[虚拟介质管理]界面,修虚拟磁盘的类型为[可共享];
— 添加到另外的虚拟机中;
———————– 创建共享磁盘 ———————–
———————– 使用udev配置共享磁盘 ———————–
— 生成udev规则文件的脚本;
for i in a b c d e f g h i j k l m n o p q r s t u v w x y z
do
echo “KERNEL==\”sd*\”, BUS==\”scsi\”, PROGRAM==\”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/\$name\”, RESULT==\”`/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/sd$i`\”, NAME=\”asm-disk$i\”, OWNER=\”grid\”, GROUP=\”asmadmin\”, MODE=\”0660\””
done
— 检查是否安装udev;
rpm -qa | grep udev
— 添加规则文件vi /etc/udev/rules.d/99-oracle-asmdevices.rules;(内容可以通过脚本生成)
KERNEL==”sd*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/$name”, RESULT==”1ATA_VBOX_HARDDISK_VBab81d7dc-431ca37f”, NAME=”asm-crs”, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
KERNEL==”sd*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/$name”, RESULT==”1ATA_VBOX_HARDDISK_VBe8fa478f-cd38bd32″, NAME=”asm-data1″, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
KERNEL==”sd*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/$name”, RESULT==”1ATA_VBOX_HARDDISK_VB57dac3e5-ff6636ce”, NAME=”asm-data2″, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
KERNEL==”sd*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/$name”, RESULT==”1ATA_VBOX_HARDDISK_VB04158991-1baaa75c”, NAME=”asm-data3″, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
KERNEL==”sd*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/$name”, RESULT==”1ATA_VBOX_HARDDISK_VB389c5a94-92168d11″, NAME=”asm-fra1″, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
KERNEL==”sd*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id –whitelisted –replace-whitespace –device=/dev/$name”, RESULT==”1ATA_VBOX_HARDDISK_VBbfb07df0-3eca3187″, NAME=”asm-fra2″, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
— 将该规则文件拷贝到其他节点上;
— 在所有节点上启动udev服务;
/sbin/start_udev
— 检查文件;
ll /dev/
———————– 使用udev配置共享磁盘 ———————–
———————– RAC的启动和关闭顺序 ———————–
1.关闭RAC:
1.关闭数据库:停止所有节点上的实例[oracle@node1 ~]$ srvctl stop database -d ORCL;
2.停止OHAS(Oracle High Availability Services):[root@node1 ~]# $GRID_HOME/crsctl stop has -f;
3.停止集群服务:root@node1 ~]# $GRID_HOME/crsctl stop cluster [-all];
2.启动RAC,默认开机会自启动,手工启动的顺序如下:
1.启动集群:root@node1 ~]# $GRID_HOME/crsctl start cluster [-all];
2.启动OHAS:root@node1 ~]# $GRID_HOME/crsctl start has;
3.启动数据库:[oracle@node1 ~]$ srvctl start database -d ORCL;
———————– RAC的启动和关闭顺序 ———————–
Oracle11g备库报ORA-00367和ORA-19527的问题
首先看一下alter.log文件中的错误信息(片段):
Tue Dec 22 06:00:47 2015
SRL log 13 needs clearing because log has not been created
Errors in file /app/sungard/oracle/diag/rdbms/futures8_standby/futures8/trace/futures8_rfs_29400.trc:
ORA-00367: checksum error in log file header
ORA-00315: log 13 of thread 0, wrong thread # 1 in header
ORA-00312: online log 13 thread 0: ‘/ora_data/oradata/futures8_standby/redo03.log’
SRL log 14 needs clearing because log has not been created
Errors in file /app/sungard/oracle/diag/rdbms/futures8_standby/futures8/trace/futures8_rfs_29400.trc:
ORA-00367: checksum error in log file header
ORA-00315: log 14 of thread 0, wrong thread # 1 in header
ORA-00312: online log 14 thread 0: ‘/ora_data/oradata/futures8_standby/redo04.log’
Oracle官方给出的引起这三个错的原因和处理的办法:
—————————————————————————————-
Error: ORA-00367
Cause: The file header for the redo log contains a checksum that does not match
the value calculated from the file header as read from disk. This means
the file header is corrupted
Action: Find the correct file and try again.
—————————————————————————————-
Error: ORA-00315
Cause: The online log is corrupted or is an old version.
Action: Find and install correct version of log or reset logs.
—————————————————————————————-
Error: ORA-00312
Cause: The control file change sequence number in the log file is greater
than the number in the control file. This implies that the wrong control
file is being used. Note that repeatedly causing this error can make it
stop happening without correcting the real problem.
Action: Use the current control file or do backup control file recovery to make the
control file current. Be sure to follow all restrictions on doing a backup
control file recovery.
—————————————————————————————-
根据官方提示可以看出,是因为控制文件中记录的SCN小于日志文件头部记录的SCN引起的,从而需要通过还原最新的控制文件来解决;这种方式是非常麻烦的,还需要还原数据文件并以resetlogs的方式打开;
除了以上办法,还可以通过清空日志文件的方式,来同步控制文件和日志头SCN:
ALTER DATABASE CLEAR LOGFILE GROUP 13;
命令执行之后会报另外的错误:
ORA-19527: physical standby redo log must be renamed
ORA-00312: online log 13 thread 0: ‘/ora_data/oradata/futures8_standby/redo03.log’
这个错误是10gR2之后功能的增强引起的:在做主备切换的时候,需要将备库的联机日志文件清除(CLEAR ONLINE REDO LOGFILE),为了加快SWITCHOVER的速度,Oracle10gR2之后在将备库置于MANGED STANDBY状态的时候就提前将这个CLEAR的动作做了,这个想法是好的,只是实现有点糟糕,然后会在alert.log文件里记录错误一堆错误;
This is in fact an Enhancement to the Data Guard Technology introduced in 10.2.0.
The Goal here is to improve speed of Switchover and Failover. In previous Versions a Role Transition would require to clear the Online Redo Logfiles before it can become a Primary Database. Now we attempt to clear the Online Redo Logfiles when starting Managed Recovery.
If the Files exist then they will be cleared, but if they do not exist we report the Error, attempts to create the Online Redo Logfiles and starts Recovery. Even if this is not possible because of different Structure and log_file_name_convert is not set, MRP does not fail; it only raises these Errors.
As an extra Enhancement if the Online Redologs do exist you must specify the log_file_name_convert Parameter even if there is no difference in the Name. This has been implemented to reduce the chances that the Primary Online Redologs are cleared when MRP starts. It is the equivalent of asking – Are you sure you want the logs to be called this….
If the log_file_name_convert parameter is not set then the ORA-19527 is reported and the log file is not cleared at this time..
Solution to stop both of these errors is to ensure log_file_name_convert is set correctly. If the File Structure is the same on the Primary and Standby Database you can set log_file_name_convert to a dummy Value;
好在给出了解决办法,只需要设置LOG_FILE_NAME_CONVERT参数即可,即便是主备目录是一致的,那么完整的解决办法如下:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
ALTER SYSTEM SET LOG_FILE_NAME_CONVERT=’/ora_data/oradata/futures8/’,’/ora_data/oradata/futures8/’,’/ora_data/oradata/futures8_standby/’,’/ora_data/oradata/futures8_standby/’ SCOPE=SPFILE;
STARTUP IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE CLEAR LOGFILE GROUP 13;
ALTER DATABASE CLEAR LOGFILE GROUP 14;
ALTER DATABASE CLEAR LOGFILE GROUP 15;
ALTER DATABASE CLEAR LOGFILE GROUP 16;
ALTER DATABASE CLEAR LOGFILE GROUP 17;
ALTER DATABASE CLEAR LOGFILE GROUP 18;
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE [USING CURRENT LOGFILE] DISCONNECT FROM SESSION;
参考文档:Note 1532566.1, Note 352879.1
DataGuard主从不同步案例处理(ORA-01274)
问题描述:
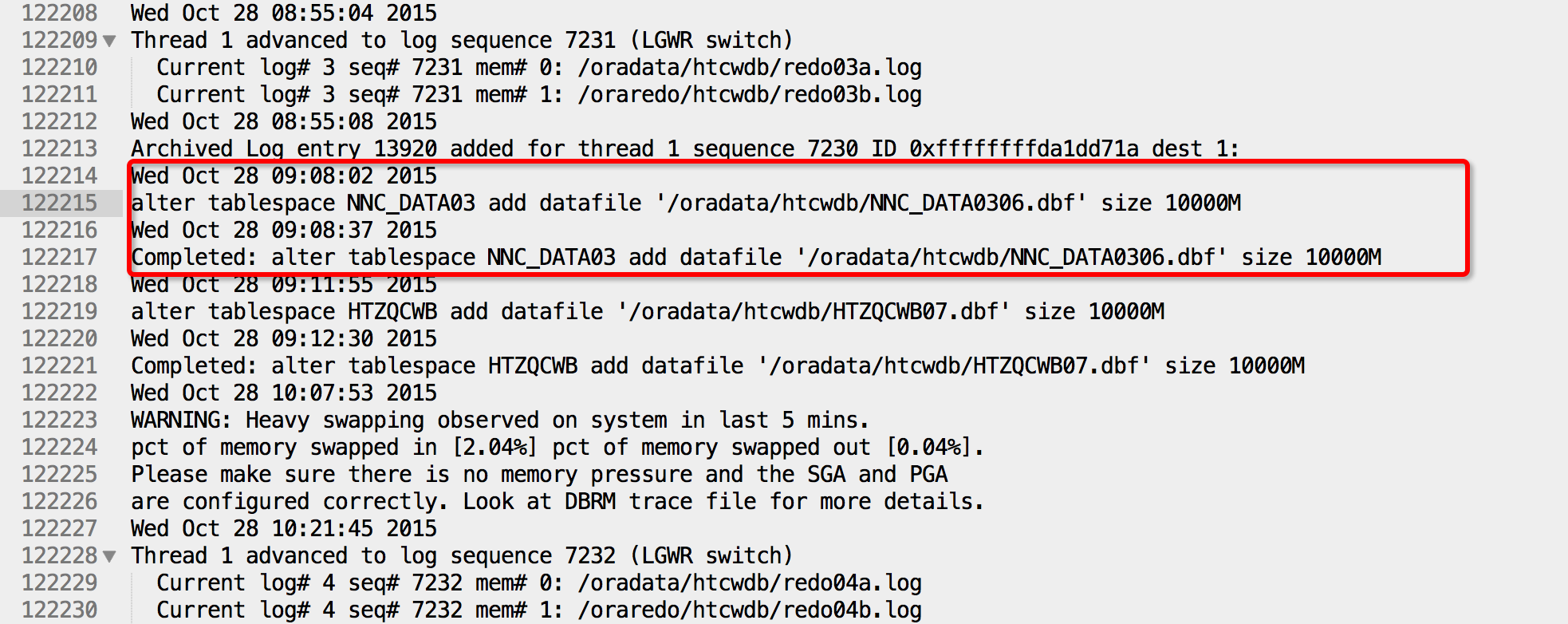
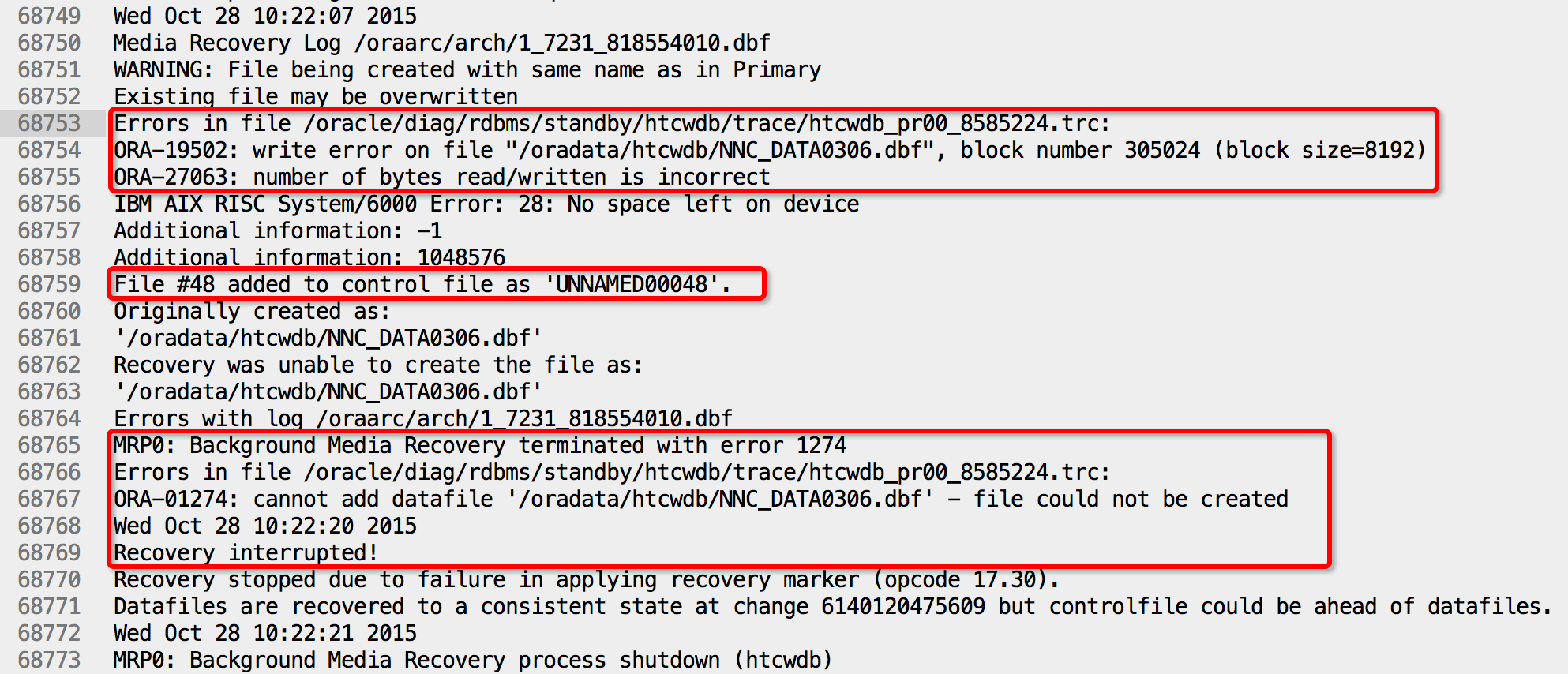
1.Oracle11.2.0.3 DataGuard环境,主库在做表空间扩容时添加了很多数据文件,但是备机空间不足,导致文件创建失败,进而无法正常同步;
2.在备库的alert文件中报ORA-01274的错误,提示创建失败的文件在控制文件中被重命名为$ORACLE_HOME/dbs/UNNAMED0048,而且MRP进程中止;
处理步骤:
1.修改备机管理模式为手动:ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT = MANUAL;
2.创建丢失文件:ALTER DATABASE CREATE DATAFILE ‘/oracle/product/11.2.0/db_1/dbs/UNNAMED00048’ AS ‘/oradata/htcwdb/NNC_DATA0306.dbf’;
3.修改备机管理模式为自动:ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT = AUTO;
4.恢复日志[并从主机接收日志]:RECOVER STANDBY DATABASE [DISCONNECT FROM SESSION];或者
5.接受日志并实时应用:ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
Oracle Enterprise Manager for MySQL Database Installation
主要内容:
1.简单介绍;
2.安装的必要条件;
3.下载并部署插件;
4.配置一个MySQL目标端;
5.删除一个目标端;
6.相关日志;
Oracle Enterprise Manager Cloud Control 12cR5 Agent Installation
主要内容:
1.12c Cloud Control Agent介绍;
2.添加主机资源;
3.添加数据库等其它资源;
Oracle Enterprise Manager Cloud Control 12cR5 Agent Installation
Oracle Enterprise Manager Cloud Control 12c Release 5 Installation on Oracle Linux 6.6
主要内容:
1.准备环境;
2.安装数据库软件;
3.创建资源库;
4.安装12c Cloud Control;
5.启动和关闭;
Oracle Enterprise Manager Cloud Control 12c Release 5 Installation on Oracle Linux 6.6
dbms_stats.import_table_stats不可以把统计信息导给别的表
今天在itpub看到一个问题 说是使用dbms_stats.import_table_stats并不会导入统计信息 然后做了一个实验如下
SQL> create table test as select * from dba_objects;
Table created.
SQL> create index idx_test on test(object_id);
Index created.
SQL> begin
dbms_stats.gather_table_stats(ownname => ‘SCOTT’,
tabname => ‘TEST’,
estimate_percent => 100,
degree => 2,
cascade => true);
end; 2 3 4 5 6 7
8 /
PL/SQL procedure successfully completed.
SQL> create table test_temp as select * from test;
Table created.
SQL> create index idx_test_temp on test_temp(object_id);
Index created.
SQL> select table_name,
num_rows,
blocks,
empty_blocks,
avg_space,
avg_row_len,
sample_size
from user_tables
where table_name in (‘TEST’, ‘TEST_TEMP’); 2 3 4 5 6 7 8 9
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE
—————————— ———- ———- ———— ———-
AVG_ROW_LEN SAMPLE_SIZE
———– ———–
TEST 75253 1098 0 0
97 75253
TEST_TEMP
SQL> begin
— dbms_stats.drop_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
dbms_stats.create_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
dbms_stats.export_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’,cascade => true);
dbms_stats.delete_table_stats(ownname=>’scott’,tabname=>’test_temp’);
dbms_stats.import_table_stats(ownname=>’scott’,tabname=>’test_temp’,stattab=>’stat_test_temp’);
end; 2 3 4 5 6 7
8 /
PL/SQL procedure successfully completed.
SQL> select table_name,
num_rows,
blocks,
empty_blocks,
avg_space,
avg_row_len,
sample_size
from user_tables
where table_name in (‘TEST’, ‘TEST_TEMP’); 2 3 4 5 6 7 8 9
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE
—————————— ———- ———- ———— ———-
AVG_ROW_LEN SAMPLE_SIZE
———– ———–
TEST 75253 1098 0 0
97 75253
TEST_TEMP
以上是你的实验
再往下看
SQL> begin
dbms_stats.drop_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
dbms_stats.create_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
dbms_stats.export_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’,cascade => true);
dbms_stats.delete_table_stats(ownname=>’scott’,tabname=>’test’);
— dbms_stats.import_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’);
end; 2 3 4 5 6 7
8 /
PL/SQL procedure successfully completed.
SQL> select table_name,
num_rows,
blocks,
empty_blocks,
avg_space,
avg_row_len,
sample_size
from user_tables
where table_name in (‘TEST’, ‘TEST_TEMP’); 2 3 4 5 6 7 8 9
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE
—————————— ———- ———- ———— ———-
AVG_ROW_LEN SAMPLE_SIZE
———– ———–
TEST
TEST_TEMP
SQL> begin
— dbms_stats.drop_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
— dbms_stats.create_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
–dbms_stats.export_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’,cascade => true);
— dbms_stats.delete_table_stats(ownname=>’scott’,tabname=>’test’);
dbms_stats.import_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’);
end; 2 3 4 5 6 7
8 /
PL/SQL procedure successfully completed.
SQL> select table_name,
num_rows,
blocks,
empty_blocks,
avg_space,
avg_row_len,
sample_size
from user_tables
where table_name in (‘TEST’, ‘TEST_TEMP’); 2 3 4 5 6 7 8 9
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE
—————————— ———- ———- ———— ———-
AVG_ROW_LEN SAMPLE_SIZE
———– ———–
TEST 75253 1098 0 0
97 75253
TEST_TEMP
由此可见这个功能不是用于把一张表的统计信息给别的表 而是用于发生了进行不同统计信息的性能测试
我们再看一个实验
先备份
SQL> begin
dbms_stats.drop_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
dbms_stats.create_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
–dbms_stats.export_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’,cascade => true);
— dbms_stats.delete_table_stats(ownname=>’scott’,tabname=>’test’);
–dbms_stats.import_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’);
end; 2 3 4 5 6 7
8 /
PL/SQL procedure successfully completed.
SQL> drop table test purge;
Table dropped.
SQL> create table test as select * from dba_objects;
Table created.
SQL> create index idx_test on test(object_id);
Index created.
SQL> select table_name,
num_rows,
blocks,
empty_blocks,
avg_space,
avg_row_len,
sample_size
from user_tables
where table_name in (‘TEST’, ‘TEST_TEMP’); 2 3 4 5 6 7 8 9
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE
—————————— ———- ———- ———— ———-
AVG_ROW_LEN SAMPLE_SIZE
———– ———–
TEST
TEST_TEMP
SQL> begin
–dbms_stats.drop_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
— dbms_stats.create_stat_table(ownname=>’scott’,stattab=>’stat_test_temp’);
–dbms_stats.export_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’,cascade => true);
— dbms_stats.delete_table_stats(ownname=>’scott’,tabname=>’test’);
dbms_stats.import_table_stats(ownname=>’scott’,tabname=>’test’,stattab=>’stat_test_temp’);
end; 2 3 4 5 6 7
8 /
PL/SQL procedure successfully completed.
SQL> select table_name,
num_rows,
blocks,
empty_blocks,
avg_space,
avg_row_len,
sample_size
from user_tables
where table_name in (‘TEST’, ‘TEST_TEMP’); 2 3 4 5 6 7 8 9
TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS AVG_SPACE
—————————— ———- ———- ———— ———-
AVG_ROW_LEN SAMPLE_SIZE
———– ———–
TEST
TEST_TEMP
SecureFile LOBs and BasicFile LOBs
oracle11g推出以后有了一种新的LOBS的存储模式叫做SecureFile LOBs 与之区别 把以前使用的叫做basicFile Lobs
根据官方文档上的说法 secure是哪哪都好。提供了压缩 重复消除 加密等新的功能 但是basicFile Lobs依然是default的
secureFime的用法是通过在LOB存储子句后添加SECUREFILE关键字来创建
最简单的一种写法:
SQL> CREATE TABLE images (
2 id NUMBER,
3 i_data CLOB
4 )
5 LOB(i_data) STORE AS BASICFILE;
Table created
SQL> CREATE TABLE images2 (id NUMBER,
2 i_data CLOB
3 )
4 LOB(i_data) STORE AS SECUREFILE;
Table created.
———————————————————————————
Securefile列标明了是否为SecureFile类型的LOB
SQL> SELECT TABLE_NAME,SEGMENT_NAME,INDEX_NAME,SECUREFILE FROM DBA_LOBS WHERE TABLE_NAME like ‘IMAGES%’;
TABLE_NAME SEGMENT_NAME
—————————— ——————————
INDEX_NAME SEC
—————————— —
IMAGES SYS_LOB0000076951C00002$$
SYS_IL0000076951C00002$$ NO
IMAGES2 SYS_LOB0000076948C00002$$
SYS_IL0000076948C00002$$ YES
Securefile
使用Securefile LOB的表也是自动生成LOB segment和LOB index的。
但是此时LOB index只有在使用重复消除功能时才会使用,在其他情况下不会使用
SQL> CREATE TABLE images2 (id NUMBER,
2 i_data CLOB
3 )
4 LOB(i_data) STORE AS SECUREFILE
5 ;
CREATE TABLE images2 (id NUMBER,
*
ERROR at line 1:
ORA-43853: SECUREFILE lobs cannot be used in non-ASSM tablespace “SYSTEM”
要注意,Securefile LOB只能在ASSM的表空间(自动管理的表空间)里创建,
不过既然从9i起ASSM表空间就是默认设置了,一般这里不会有多大问题。
只是要求SecureLOB所在的LOB列数据需要存放在ASSM表空间中,而包含LOB列的那个表可以不是
CREATE TABLE images2 (id NUMBER,i_data CLOB) LOB(i_data) STORE AS SECUREFILE (tablespace ucjmh);
SQL> conn / as sysdba
Connected.
SQL> CREATE TABLE images2 (id NUMBER,i_data CLOB) LOB(i_data) STORE AS SECUREFILE (tablespace ucjmh);
Table created.
————————————————————————————————–
SQL> show parameter DB_SECUREFILE
NAME TYPE VALUE
———————————— ———– ——————————
db_securefile string PERMITTED
这个值的取值范围有:
DB_SECUREFILE = { NEVER | PERMITTED | ALWAYS | IGNORE }
PERMITTED 是默认的 就是当你指定是什么的时候就是什么
FORCE 是ORA-43853的来源 意思就是不管你是否指定用SecureFile 创建的时候都是用Securefile 如果不是在ASSM的表空间 那么就报ORA-43853
ALWAYS 意思就是不管你是否指定用SecureFile 创建的时候都是用Securefile 但是如果你是非ASSM的表空间 那就是BASICFILE 如果非ASSM的时候你还显示的指定了用SecureFiLE 那也报43853
NEVER 是不管怎么样都是BasicFile 如果指定了一些加密或压缩之类的参数那么就报ORA-43853
IGNORE 是不管怎么样都是BasicFile 如果指定了一些加密或压缩之类的参数也不报错。
chunk:
在BasicFile的LOB中,Chunk的大小是一定的,最小跟DB Block的大小一样,最大为32KB
–一个chunk最多只保留一行LOB数据,也就是说,如果你设置了32K的CHUNK,但是如果LOB字段大小只有4K,也将占用32K的空间
而在SecureFile中,chunk的size是可变的,由Oracle自动动态分配,最小跟DB Block的大小一样,最大为64MB
–指定的值最好是数据库块的倍数,而且指定的值不能大于表空间区间中NEXT的值
当指定enable storage in row的时候,当lob size =4000 bytes的时候,将存储在lob段里面,其存储方式和表段存储方式完全不一样,使用的是chunk为最小单位的存储,没有行迁移和行链接的概念。
如果设置了enable storage in row 那么oracle会自动将小于4000bytes的数据存储在行内, 这是ORACLE的默认值,
对于大于4000字节的lob字段保存在lob段(同disable storage in row),在表段将保留36-84字节的控制信息。
对于disable storage in row,Oracle将lob字段分开保存在lob段中,而仅仅在行位置保留20字节的指针。
对于相当于disable storage in row的这部分(也就是单独保存在LOB段的这部分数据),UNDO仅仅是记录指针与相关lob索引改变,如果发生更新操作等DML操作,原始数据将保留在LOB段
DISABLE STORAGE IN ROW:如果DISABLE这个属性,那么lob数据会在行外存储,行内只存储该lob值得指针,而且这个属性在表
storage as(cache|nocahce)表示是否允许lob段经过buffer cache并缓存。默认是nocache,表示直接读与直接写,不经过数据库的data buffer。所以,默认情况下,对于单独保存在LOB段的这部分数据,在发生物理读的时候,是直接读,如direct path read (lob)
storage as(nocache logging |nocache nologging),logging/nologging属性只对nocache方式生效,默认是logging,如果是nologging方式,对于 保存在行外的log部分,在update等DML操作时将不记录redo日志
PCTVERSION integer、RETENTION:都是ORACLE用来管理LOB字段镜像数据的。在LOB 数据的更新过程中,
ORACLE没有用UNDO TABLESPACE空间,而是从LOB字段所在的表空间里划分一段空间来做镜像空间的,
这个空间的大小由PCTVERSION参数控制,默认值为10,代表划分表空间的10%作为镜像空间,
每个镜像空间的单元大小由CHUNK参数指定,pctversion可以使用在manual undo mode和automatic undo mode 环境中
retention应用了automatic undo mode中的undo_retention通过时间来管理lob镜像空间.
pctversion和retention不能同时被指定.建议数据库在automatic undo mode下使用retention参数
SecureFile的COMPRESS选项在表或分区一级上开启了对LOB内容的压缩,使用关键字MEDIUM和HIGH表示压缩的等级,
如果没有指定压缩等级,就默认为MEDIUM,对LOB内容进行压缩会增加系统开销,
因此使用高等级的压缩可能会对系统性能产生不良影响,SecureFile LOB的压缩功能不影响表压缩,反之亦然
SecureFile LOB的加密功能依赖于钱夹或硬件安全模型(HSM)掌管加密密钥,钱夹设置与透明数据加密(TDE)和表空间加密描述的一样,
因此在尝试下面的例子前先完成那两个实验。SecureFile的ENCRYPT选项执行块级别的LOB内容加密,
一个可选的USING子句定义了使用哪种加密算法(3DES168, AES128, AES192, 或AES256),默认使用AES192算法,
NO SALT选项对于SecureFile加密不可用,加密是应用在每一列上的,因此它会影响所有使用LOB的分区,DECRPT选项用于明确地阻止加密
加密是不受imp/exp或表空间传输支持的,因此必须使用impdp/exddp来传输数据
BasicFile和SecureFile LOB共享了部分基础的缓存和日志选项,常见的缓存选项有:
CACHE – LOB数据被放在缓冲区中。
CACHE READES – 仅读取LOB数据过程中它放在缓冲区中,写操作时不放进去。
NOCACHE – LOB数据不放在缓冲区中,这是BasicFile和SecureFile LOB的默认值。
基本的日志选项有:
LOGGING – 创建和修改LOB时产生完全重做日志,这是默认设置。
NOLOGGING – 操作不记录在重做日志中,因此不能恢复,在首次创建和巨大的载入过程中有用。
而且,SecureFile LOB还有一个日志选项FILESYSTEM_LIKE_LOGGING,只记录元数据,在出现故障后仍然允许段的恢复。
CACHE选项意味着LOGGING,因此你不能将CACHE与NOLOGGING或FILESYSTEM_LIKE_LOGGING合在一起使用。
如果要移动表
ALTER TABLE table_name LOB (lob_item) STORE AS [lob_segment]
(
TABLESPACE tablespace_name
(STORAGE…..)
ENABLE|DISABLE STORAGE IN ROW
CHUNK integer
PCTVERSION integer
RETENTION
FREEPOOLS integer
CACHE|NOCACHE|CACHE READS
INDEX lobindexname
(TABLESPACE tablesapce_name
((STORAGE…..))
)