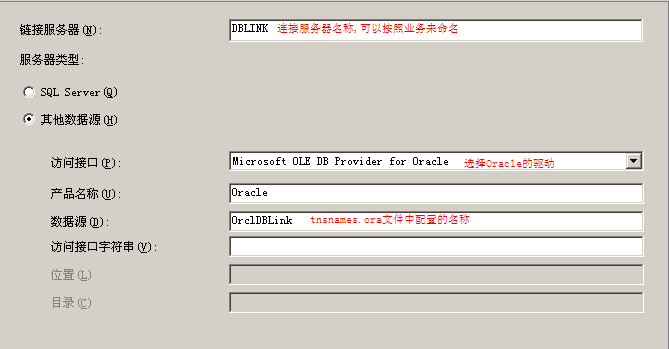
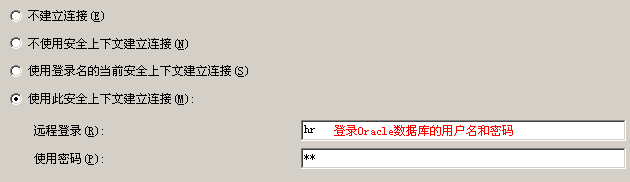
创建数据库与多个文件组,在各个文件组中放置不同的数据表,故意损坏其中一个文件后,
通过设置,可以让改数据库内其它完好的文件组继续提供访问,并经过还原备份数据,可以单独回复该数据文件与文件组
1.创建NWind测试数据库,并添加3个文件组

2.在不同的FileGroup中分别放置一个数据表
3.查看各个数据表所属的FileGroup

4.分析各个数据文件的属性

5.向数据库中插入数据
6.分析各个表中的数据

7.备份NWind数据库

8.暂停MSSQLSERVER服务,并删掉NWind_B.ndf文件模拟数据库损坏

9.出现错误

10.检查NWind数据库处于RECOVERY_PENDING状态

11.设置文件NWind_B为OFFLINE,并设置NWind数据库状态为ONLINE

12.分析各个数据文件的在线状态

13.分析各个表的数据,查询TbB时候出错

14.向数据库中插入数据,向TbB中插入数据时出错
15.备份日志文件
NO_TRUNCATE 指定不截断日志,并使数据库引擎尝试执行备份,而不考虑数据库的状态.
因此,使用 NO_TRUNCATE 执行的备份可能具有不完整的元数据.该选项允许在数据库损坏时备份日志.
BACKUP LOG 的 NO_TRUNCATE 选项相当于同时指定 COPY_ONLY 和 CONTINUE_AFTER_ERROR.
如果不使用 NO_TRUNCATE 选项,则数据库必须联机.
16.查询备份文件的头信息

17.查询备份文件的文件信息

18.还原损坏的数据库

19.分析各个数据文件的属性,Nwind_B处于RESTORING状态

20.还原NWind的日志文件

21.分析各个数据文件的属性

22.分析各个表中的数据