SQL*Loader工具与外部表
- SQL*Loader:
- 概念:
- 可以在服务器端和客户端操作,数据可以存放在服务器端或者客户端;
- 可以导入固定格式的TXT文件的数据;
- INSERT INTO … SELECT …的两种插入数据的方法:
- conventional INSERT操作:通用的插入方法,数据库会优先重新利用HWM(High Water Mark)以下的数据块,然后再使用HWM以上的数据块,使得新旧数据交叉存放,同时还要维护数据的完整性(主外键,CHECK约束等);
- direct-path INSERT操作:直接路径插入方法,数据库把数据直接插入到高水位之后的数据块中,数据不经过buffer cache,直接写入数据文件,忽略数据的完整性,使得性能最大的提升;
- 顺序插入分区/非分区表:只有一个线程把数据写到HWM之后;
- 并行插入分区表:每个进程可以被分配到一个或者多个分区,但是一个分区最多只有一个进程负责,推荐使用跟分区数量相同的并行度;数据同样只在每个分区的HWM之后的数据块写入;
- 并行插入非分区表:每个进程分配一个临时的段,然后把所有临时段合并;
- SQL*Loader的convention-path load方式和direct-path load方式跟这个相似;
- 可以通过使用/*+ APPEND */的hint,来使用直接导入数据,例子;
- conventional方式使用会产生redo日志,而direct-path方式始终不产生日志,与表本身是否是LOGGING模式无关,如果数据库是FORCE LOGGING模式,则无论那种方式都会记录日志,例子;
- SQL*Loader的介绍;
- Input data files:要导入的数据文件;
- 以文本形式存在;
- 可以有多个数据文件;
- 支持三种数据格式:
- Fixed-Record Format:每个列有固定的长度,效率高单灵活性差,如:数据文件中每11个字节是一个字段infile ‘example.dat’ “fix 11”;
- Variable-Record Format:每个列长度不固定,在最前面n位来记录它的长度,如:前三个字符表示记录的长度infile ‘example.dat’ “var 3”;
- Stream-Record Format:流记录,以某个符号区分列,最常用的方式;
- 记录的种类:
- Physical Record:即数据文本中的一行记录;
- Logical Record:在数据库中表的一行记录,可以合并几行物理记录组成一个逻辑记录;
- Loader control file:导入数据的控制文件;
- 指定导入数据的目录;
- 数据的格式化;
- 配置信息:内存,拒绝记录的规则,异常终止后的处理;
- 如何操作数据;
- 注释使用[–]符号;
- 不能使用CONSTANT和ZONE关键字;
- Parameter file:可选,可以把sqlldr命令后面的参数保存起来,只需要指定参数文件即可;
- Discard file:可选,被抛弃的数据,不满足过滤器条件的记录;
- 可以控制打开或者关闭此功能;
- 可以在控制文件中定义记录选择的标准;
- 可以规定当discard file中记录超过一定数量的话就终止;
- Bad file:可选,被拒绝的数据;
- SQL*Loader拒绝的数据,比如输入数据的格式不对;
- Oracle数据库拒绝的数据,比如违反约束的记录;
- Log file:可选,日志信息,如果没有指定就会生成以.log结尾的跟数据文件同名的文件;
- 头信息;
- 全局信息;
- 表信息;
- 数据文件信息;
- 表加载的信息;
- 统计信息;
- 附加信息,比如花费的时间等待;
- 架构图;
.png)
- Conventional和Direct-Path Load方法的对比:
- Conventional Load:
- 读取一条记录,解析,插入,提交;
- 总是会产生REDO日志;
- 强制检查所有约束;
- 会激活触发器;
- 可以插入到簇表;
- 其它用户可以修改表;
- Direct-Path Load:
- 把记录构造成块,直接进行块拷贝;
- 只有在数据库为FORCE LOGGING模式下才会产生REDO日志;
- 只检查主键,唯一键,NOT NULL约束;
- 忽略触发器;
- 不能对簇表加载数据;
- 其它用户不能修改表;
- 可以使用并行操作来加快速度,但是需要手动指定并行度;
- SQL*Loader的语法:sqlldr keyword=value,命令后面是键值对的组合;
- userid:username/password;
- control:控制文件名称;
- log:日志文件名称;
- bad:bad文件名称;
- data:数据文件名称;
- discard:discard文件名称;
- discardmax:允许最大的discard的记录数,默认为所有记录;
- skip:跳过的逻辑记录数,默认为0;
- load:加载的逻辑记录数,默认为所有记录;
- errors:允许错误的记录数,默认为50;
- silent:不提示header/feedback/errors/discards/partitions等信息,默认为FALSE;
- direct:使用直接路径,默认为FALSE;
- multithreading:直接数据导入时使用多线程;
- parfile:使用的参数文件的名称;
- parallel:使用并行加载,默认是FALSE;
- skip_unusable_indexes:跳过unusable的索引,默认为FALSE;
- skip_index_maintenance:不维护索引,标记索引为unusable,默认为FALSE;
- commit_discontinued:当加载数据终止时,提交已经加载了的数据,默认为FALSE;
- streamsize:使用直接路径加载时的缓存区大小,默认是256000;
- external_table:使用外部表导入数据;
- NOT_USED:不使用外部表;
- GENERATE_ONLY:只生成外部表的创建语法,生成在log文件中;
- EXECUTE:使用外部表导入数据;
- date_cache:导入数据的cache大小;
- _display_exitcode:显示sqlloader退出时的退出码;
- SQL*Loader的退出码,用在SHELL编程中:
- EX_SUCC(0):所有的记录加载成功;
- EX_WARN(2):一些记录被放到bad file/discard file/异常终止;
- EX_FAIL(1):语法错误,操作错误;
- 如果状态码大于0的话,就有问题;
- SQL*Loader的例子:
- 在9i的数据库的$ORACLE_HOME/rdbms/demo/目录下ul*的11个例子(.ctl是控制文件,.sql是修改表的脚本,.dat是数据,在scott用户下完成);
- EXAMPLE1:加载变长的数据,数据列之间以逗号分隔,可能还以引号包围,数据和控制文件在一起;
- EXAMPLE2:加载固定格式的数据,数据和控制文件分开;
- EXAMPLE3:加载有定界符的,随意格式的文件,数据与控制文件在一起;
- EXAMPLE4:加载合并的物理记录,合并多个物理记录到一个逻辑记录中;
- EXAMPLE5:加载数据到多个表中;
- EXAMPLE6:使用直接路径的方式加载数据;
- EXAMPLE7:从一个格式化的报表中抽取数据并加载;
- EXAMPLE8:加载分区表;
- EXAMPLE9:加载CLOB列;
- EXAMPLE10:加载REF列和ARRAYs列;
- EXAMPLE11:转换字符集,使用Unicode编码加载数据;
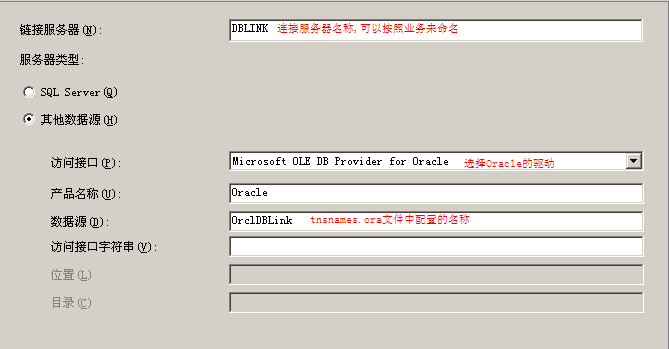
- DIRECTORY对象:
- 只有SYS用户可以拥有DIRECTORY对象,但是它可以授权其它用户创建的权限;
- DIRECTORY对象只是一个文件系统目录的映射/别名(如果oracle用户没有这个目录的权限怎么办?);
- 具有DBA角色或者CREATE ANY DIRECTORY权限的用户可以创建DIRECTORY对象:CREATE DIRECTORY ext_tab_dir AS ‘/u01/datafiles’;
- 查看系统中存在的DIRECTORY对象:SELECT * FROM dba_directories;
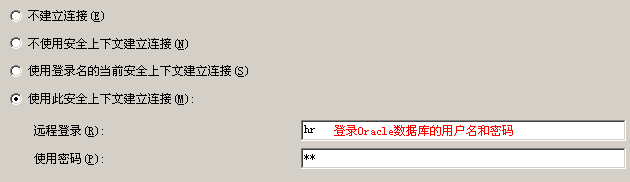
- 创建者/DBA可以对其它用户/角色授权:GRANT READ, WRITE ON DIRECTORY ext_tab_dir TO hr;
- 查看某个DIRECTORY对象的权限:SELECT * FROM dba_tab_privs WHERE table_name = ‘EXT_TAB_DIR’;
- 创建者和DBA自动具有RW权限;
- 删除DIRECTORY对象:DROP DIRECTORY ext_tab_dir;
- 外部表(External Tables):
- 外部表的概念:
- 10g之前,外部表是只读的;10g之后,外部表可读可写;
- 外部表是对SQL*Loader功能的补充,可以像访问数据库中表一样访问数据库外的资源;
- 只能在服务器端操作,数据要存放在服务器端,因为需要使用DIRECTORY;
- 可以导入固定格式的TXT文件的数据;
- 在ETL中尽量多用外部表,而少用SQL*Loader;
- 创建外部表:
- 使用CREATE TABLE table_name(…) ORGANIZATION EXTERNAL语法,需要指定的属性:
- TYPE:指定外部表使用的访问引擎;
- ORACLE_LOADER:默认值,只能进行数据加载操作,而且数据必须是文本文件;
- ORACLE_DATAPUMP:可以进行数据加载/卸载的操作,数据必须是二进制的dump文件;
- DEFAULT DIRECTORY:指定外部表所使用的默认目录,是一个DIRECTORY对象,而不是一个路径;
- ACCESS PARAMETERS:指定外部表数据对应的表中的列和某一列的格式化信息,与使用的引擎有关;
- LOCATION:指定外部表的位置,是目录和文件名的组合(directory:file),如果没有指定目录则使用默认的目录;
- 创建的步骤:
- 创建DIRECTORY对象;
- 创建外部表;
- 其它操作:可以再创建一个表,然后使用INSERT INTO … SELECT …语法导入数据;
- 加载和卸载数据:
- 加载数据:把外部表中的数据导入到数据库的表中;
- 卸载数据:把数据库表中的内容导入到外部不表中,只能使用ORACLE_DATAPUMP引擎;
- 使用外部表时的数据类型转换,LOB字段:CREATE TABLE LONG_TAB_XT (LONG_COL CLOB) ORGANIZATION EXTERNAL…SELECT TO_LOB(LONG_COL) FROM LONG_TAB;
- 并行查询外部表:
- ORACLE_LOADER引擎:
- 如果加载文件时顺序指定了多个文件;
- 记录使用VAR格式化;
- ORACLE_DATAPUMP引擎:
- 加载数据时:
- 加载时使用了多个文件;
- 使用一个大的文件时也会并行,因为会记录文件读取的偏移量;
- 卸载数据时:
- LOCATION参数指定多个文件时可以发生并行;
- 如果并行度等于文件的个数的话,每个进程写一个文件;
- 如果并行度大于文件的个数的话,并行度降低为文件的个数;
- 如果并行度小于文件的个数的话,外部文件将不会被使用;
- 自己决定并行度;
- 外部表的限制:
- 不支持加密列;
- 不支持LONG类型的列;
- 特殊字符需要用双引号转换;
- 不能是临时表;
- 不能添加约束;
- SQL*Loader和外部表的不同:
- 在sql*loader中可以使用反斜杠来转义一个字符:FIELDS TERMINATED BY ‘,’ OPTIONALLY ENCLOSED BY ‘\”;
- 在外部表中使用反斜杠会报错,可以使用引号来分割字段:TERMINATED BY ‘,’ ENCLOSED BY “‘”;
- 外部表的例子:
- ORACLE_LOADER引擎:使用脚本导入的例子;
- ORACLE_LOADER引擎:使用sql*loader生成外部表脚本的例子;
- ORACLE_DATADUMP引擎:导出数据的例子;
- ORACLE_DATADUMP引擎:导入数据的例子;
————————- Direct-Path INSERT的例子 ————————-
— 创建一个空表;
CREATE TABLE bt AS SELECT * FROM dba_objects WHERE 1 = 0;
— 正常插入数据;
INSERT INTO bt SELECT * FROM dba_objects;
— 在提交之前就可以查询到表的数量;
SELECT COUNT(*) FROM bt;
COMMIT;
.png)
— 使用直接路径的方式;
INSERT /*+ APPEND */ INTO bt SELECT * FROM dba_objects;
— 提交之前查询表报错,从一方面说明了直接路径插入;
SELECT COUNT(*) FROM bt;
SELECT COUNT(*) FROM bt
*
ERROR at line 1:
ORA-12838: cannot read/modify an object after modifying it in parallel
.png)
————————- Direct-Path INSERT的例子 ————————-
————————- Direct-Path INSERT NOLOGGING的例子 ————————-
— 一,表处于LOGGING模式,数据库不是FORCE LOGGING模式,观察几种插入方式产生的日志;
— 1.传统插入,LOGGING模式,会产生日志;
— 2.传统插入,NOLOGGING模式,同样会产生日志;
— 3.直接插入,LOGGING模式,不会产生日志;
— 4.直接插入,NOLOGGING模式,也不会产生日志;
— 二,表处于NOLOGGING模式,数据库处于非FORCE LOGGING模式:传统方式都会产生日志,直接插入方式都不产生日志;
— 三,数据库处于FORCE LOGGING模式,无论表是什么模式,无论哪种方式都会记录日志;
————————- Direct-Path INSERT NOLOGGING的例子 ————————-
————————- SQL*Loader的例子 ————————-
— EXAMPLE1:加载变长的数据,数据列之间以逗号分隔,可能还以引号包围,数据和控制文件在一起;
— 创建测试表;
DROP TABLE EMP;
DROP TABLE DEPT;
CREATE TABLE DEPT
(
DEPTNO NUMBER(2) not null,
DNAME VARCHAR2(14),
LOC VARCHAR2(13)
);
CREATE TABLE EMP
(
EMPNO NUMBER(4) not null,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
);
— 控制文件和数据;
LOAD DATA
INFILE *
INTO TABLE DEPT
FIELDS TERMINATED BY ‘,’ OPTIONALLY ENCLOSED BY ‘”‘
(DEPTNO, DNAME, LOC)
BEGINDATA
12,RESEARCH,”SARATOGA”
10,”ACCOUNTING”,CLEVELAND
11,”ART”,SALEM
13,FINANCE,”BOSTON”
21,”SALES”,PHILA.
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo1.ctl;
— 验证数据;
— EXAMPLE2:加载固定格式的数据,数据和控制文件分开;
— 控制文件;
LOAD DATA
INFILE ‘/u01/sqlldrdemo/demo2.dat’
INTO TABLE EMP
( EMPNO POSITION(01:04) INTEGER EXTERNAL,
ENAME POSITION(06:15) CHAR,
JOB POSITION(17:25) CHAR,
MGR POSITION(27:30) INTEGER EXTERNAL,
SAL POSITION(32:39) DECIMAL EXTERNAL,
COMM POSITION(41:48) DECIMAL EXTERNAL,
DEPTNO POSITION(50:51) INTEGER EXTERNAL)
— 数据文件;
7782 CLARK MANAGER 7839 2572.50 10
7839 KING PRESIDENT 5500.00 10
7934 MILLER CLERK 7782 920.00 10
7566 JONES MANAGER 7839 3123.75 20
7499 ALLEN SALESMAN 7698 1600.00 300.00 30
7654 MARTIN SALESMAN 7698 1312.50 1400.00 30
7658 CHAN ANALYST 7566 3450.00 20
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo2.ctl;
— 验证数据;
— EXAMPLE3:加载有定界符的,随意格式的文件,数据与控制文件在一起;
— 修改表结构:alter table emp add (projno number, loadseq number);
— 控制文件;
LOAD DATA
INFILE *
APPEND
INTO TABLE EMP
FIELDS TERMINATED BY “,” OPTIONALLY ENCLOSED BY ‘”‘
(empno, ename, job, mgr,
hiredate DATE(20) “DD-Month-YYYY”,
sal, comm,
deptno CHAR TERMINATED BY ‘:’,
projno,
loadseq SEQUENCE(MAX,1))
BEGINDATA
7782, “Clark”, “Manager”, 7839, 09-June-1981, 2572.50,, 10:101
7839, “King”, “President”, , 17-November-1981, 5500.00,, 10:102
7934, “Miller”, “Clerk”, 7782, 23-January-1982, 920.00,, 10:102
7566, “Jones”, “Manager”, 7839, 02-April-1981, 3123.75,, 20:101
7499, “Allen”, “Salesman”, 7698, 20-February-1981, 1600.00, 300.00, 30:103
7654, “Martin”, “Salesman”, 7698, 28-September-1981, 1312.50, 1400.00, 30:103
7658, “Chan”, “Analyst”, 7566, 03-May-1982, 3450,, 20:101
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo3.ctl;
— 验证数据;
— EXAMPLE4:加载合并的物理记录,合并多个物理记录到一个逻辑记录中;
— 修改表结构;
DROP TABLE EMP;
CREATE TABLE EMP
(
EMPNO NUMBER(4) not null,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
);
CREATE UNIQUE INDEX UNQ_EMPNO ON EMP(EMPNO);
— 控制文件;
LOAD DATA
INFILE “/u01/sqlldrdemo/demo4.dat”
DISCARDFILE “/u01/sqlldrdemo/demo4.dis”
DISCARDMAX 999
REPLACE
CONTINUEIF (1) = ‘*’
INTO TABLE EMP
( EMPNO POSITION(01:04) INTEGER EXTERNAL,
ENAME POSITION(06:15) CHAR,
JOB POSITION(17:25) CHAR,
MGR POSITION(27:30) INTEGER EXTERNAL,
SAL POSITION(32:39) DECIMAL EXTERNAL,
COMM POSITION(41:48) DECIMAL EXTERNAL,
DEPTNO POSITION(50:51) INTEGER EXTERNAL,
HIREDATE POSITION(52:60) INTEGER EXTERNAL)
— 数据文件;
*7782 CLARK MA
NAGER 7839 2572.50 -10 2512-NOV-85
*7839 KING PR
ESIDENT 5500.00 2505-APR-83
*7934 MILLER CL
ERK 7782 920.00 2508-MAY-80
*7566 JONES MA
NAGER 7839 3123.75 2517-JUL-85
*7499 ALLEN SA
LESMAN 7698 1600.00 300.00 25 3-JUN-84
*7654 MARTIN SA
LESMAN 7698 1312.50 1400.00 2521-DEC-85
*7658 CHAN AN
ALYST 7566 3450.00 2516-FEB-84
* CHEN AN
ALYST 7566 3450.00 2516-FEB-84
*7658 CHIN AN
ALYST 7566 3450.00 2516-FEB-84
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo4.ctl;
— 验证数据;
— 检查不满足条件的记录;
— EXAMPLE5:加载数据到多个表中;
— 创建测试表;
DROP TABLE emp;
DROP TABLE proj;
CREATE TABLE EMP
(
EMPNO NUMBER(4) not null,
ENAME CHAR(10),
JOB CHAR(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
);
CREATE UNIQUE INDEX unq_empno ON EMP (EMPNO);
CREATE TABLE PROJ
(
EMPNO NUMBER,
PROJNO NUMBER
);
— 控制文件;
LOAD DATA
INFILE ‘/u01/sqlldrdemo/demo5.dat’
BADFILE ‘/u01/sqlldrdemo/demo5.bad’
DISCARDFILE ‘/u01/sqlldrdemo/demo5.dis’
REPLACE
INTO TABLE EMP
(EMPNO POSITION(1:4) INTEGER EXTERNAL,
ENAME POSITION(6:15) CHAR,
DEPTNO POSITION(17:18) CHAR,
MGR POSITION(20:23) INTEGER EXTERNAL)
INTO TABLE PROJ
— PROJ has two columns, both not null: EMPNO and PROJNO
WHEN PROJNO != ‘ ‘
(EMPNO POSITION(1:4) INTEGER EXTERNAL,
PROJNO POSITION(25:27) INTEGER EXTERNAL) — 1st proj
INTO TABLE PROJ
WHEN PROJNO != ‘ ‘
(EMPNO POSITION(1:4) INTEGER EXTERNAL,
PROJNO POSITION(29:31) INTEGER EXTERNAL) — 2nd proj
INTO TABLE PROJ
WHEN PROJNO != ‘ ‘
(EMPNO POSITION(1:4) INTEGER EXTERNAL,
PROJNO POSITION(33:35) INTEGER EXTERNAL) — 3rd proj
— 数据文件;
1234 BAKER 10 9999 101 102 103
1234 JOKER 10 9999 777 888 999
2664 YOUNG 20 2893 425 abc 102
5321 OTOOLE 10 9999 321 55 40
2134 FARMER 20 4555 236 456
2414 LITTLE 20 5634 236 456 40
6542 LEE 10 4532 102 321 14
2849 EDDS xx 4555 294 40
4532 PERKINS 10 9999 40
1244 HUNT 11 3452 665 133 456
123 DOOLITTLE 12 9940 132
1453 MACDONALD 25 5532 200
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo5.ctl;
— 验证数据;
— 检查不满足条件的记录;
— EXAMPLE6:使用直接路径的方式加载数据;
— 创建测试表;
DROP TABLE emp;
CREATE TABLE EMP
(
EMPNO NUMBER(4) not null,
ENAME CHAR(10),
JOB CHAR(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
)
CREATE UNIQUE INDEX unq_empno ON emp(empno);
— 控制文件;
LOAD DATA
INFILE ‘/u01/sqlldrdemo/demo6.dat’
REPLACE
INTO TABLE emp
SORTED INDEXES (unq_empno)
(empno position(1:4),
ename position(6:15),
job position(17:25),
mgr position(27:30) nullif mgr=blanks,
sal position(32:39) nullif sal=blanks,
comm position(41:48) nullif comm=blanks,
deptno position(50:51) nullif empno=blanks)
— 数据文件;
7566 JONES MANAGER 7839 3123.75 20
7654 MARTIN SALESMAN 7698 1312.50 1400.00 30
7658 CHAN ANALYST 7566 3450.00 20
7782 CLARK MANAGER 7839 2572.50 10
7839 KING PRESIDENT 5500.00 10
7934 MILLER CLERK 7782 920.00 10
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo6.ctl direct=y;
— 验证数据;
— EXAMPLE7:从一个格式化的报表中抽取数据并加载;
— 创建测试表;
CREATE TABLE EMP
(
EMPNO NUMBER(4) not null,
ENAME CHAR(10),
JOB CHAR(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
);
CREATE UNIQUE INDEX UNQ_EMPNO on EMP (EMPNO);
— 添加触发器,这一步是关键;
CREATE OR REPLACE PACKAGE sqlloader AS
last_deptno NUMBER;
last_job CHAR(9);
last_mgr NUMBER;
END sqlloader;CREATE OR REPLACE TRIGGER sqlloader_emp_insert
BEFORE INSERT ON emp
FOR EACH ROW
BEGIN
IF :new.deptno IS NOT NULL THEN
sqlloader.last_deptno := :new.deptno; — save value for later use
ELSE
:new.deptno := sqlloader.last_deptno; — use last valid value
END IF;
IF :new.job IS NOT NULL THEN
sqlloader.last_job := :new.job; — save value for later use
ELSE
:new.job := sqlloader.last_job; — use last valid value
END IF;
IF :new.mgr IS NOT NULL THEN
sqlloader.last_mgr := :new.mgr; — save value for later use
ELSE
:new.mgr := sqlloader.last_mgr; — use last valid value
END IF;
END sqlloader_emp_insert;
— 控制文件;
LOAD DATA
INFILE ‘/u01/sqlldrdemo/demo7.dat’
DISCARDFILE ‘/u01/sqlldrdemo/demo7.dis’
APPEND
INTO TABLE emp
WHEN (57)=’.’
TRAILING NULLCOLS
(hiredate SYSDATE,
deptno POSITION(1:2) INTEGER EXTERNAL(3)
NULLIF deptno=BLANKS,
job POSITION(7:14) CHAR TERMINATED BY WHITESPACE
NULLIF job=BLANKS “UPPER(:job)”,
mgr POSITION(28:31) INTEGER EXTERNAL TERMINATED BY WHITESPACE
NULLIF mgr=BLANKS,
ename POSITION (34:41) CHAR TERMINATED BY WHITESPACE
“UPPER(:ename)”,
empno INTEGER EXTERNAL TERMINATED BY WHITESPACE,
sal POSITION(51) CHAR TERMINATED BY WHITESPACE
“TO_NUMBER(:sal,’$99,999.99′)”,
comm INTEGER EXTERNAL ENCLOSED BY ‘(‘ AND ‘%’
“:comm * 100”
)
— 数据文件;
Today’s Newly Hired EmployeesDept Job Manager MgrNo Emp Name EmpNo Salary/Commission
—- ——– ——– —– ——– —– —————–
20 Salesman Blake 7698 Shepard 8061 $1,600.00 (3%)
Falstaff 8066 $1,250.00 (5%)
Major 8064 $1,250.00 (14%)
30 Clerk Scott 7788 Conrad 8062 $1,100.00
Ford 7369 DeSilva 8063 $800.00
Manager King 7839 Provo 8065 $2,975.00
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo7.ctl;
— 验证数据;
.png)
— 查看不满足的记录;
— EXAMPLE8:加载分区表;
— 创建测试表;
CREATE TABLE LINEITEM
(
L_ORDERKEY NUMBER,
L_PARTKEY NUMBER,
L_SUPPKEY NUMBER,
L_LINENUMBER NUMBER,
L_QUANTITY NUMBER,
L_EXTENDEDPRICE NUMBER,
L_DISCOUNT NUMBER,
L_TAX NUMBER,
L_RETURNFLAG CHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATE DATE,
L_COMMITDATE DATE,
L_RECEIPTDATE DATE,
L_SHIPINSTRUCT CHAR(17),
L_SHIPMODE CHAR(7),
L_COMMENT CHAR(43)
)
PARTITION by RANGE (L_SHIPDATE)
(
PARTITION SHIP_Q1 VALUES LESS THAN (TO_DATE(‘1996-04-01 00:00:00’, ‘YYYY-MM-DD HH24:MI:SS’)),
PARTITION SHIP_Q2 VALUES LESS THAN (TO_DATE(‘1996-07-01 00:00:00’, ‘YYYY-MM-DD HH24:MI:SS’)),
PARTITION SHIP_Q3 VALUES LESS THAN (TO_DATE(‘1996-10-01 00:00:00’, ‘YYYY-MM-DD HH24:MI:SS’)),
PARTITION SHIP_Q4 VALUES LESS THAN (TO_DATE(‘1997-01-01 00:00:00’, ‘YYYY-MM-DD HH24:MI:SS’))
);
— 控制文件;
LOAD DATA
INFILE ‘/u01/sqlldrdemo/demo8.dat’ “fix 129”
BADFILE ‘/u01/sqlldrdemo/demo8.bad’
TRUNCATE
INTO TABLE lineitem
PARTITION (ship_q1)
(l_orderkey position (1:6) char,
l_partkey position (7:11) char,
l_suppkey position (12:15) char,
l_linenumber position (16:16) char,
l_quantity position (17:18) char,
l_extendedprice position (19:26) char,
l_discount position (27:29) char,
l_tax position (30:32) char,
l_returnflag position (33:33) char,
l_linestatus position (34:34) char,
l_shipdate position (35:43) char,
l_commitdate position (44:52) char,
l_receiptdate position (53:61) char,
l_shipinstruct position (62:78) char,
l_shipmode position (79:85) char,
l_comment position (86:128) char)
— 数据文件;
1 151978511724386.60 7.04.0NO09-SEP-6412-FEB-9622-MAR-96DELIVER IN PERSON
TRUCK iPBw4mMm7w7kQ zNPL i261OPP
1 2731 73223658958.28.09.06NO12-FEB-9628-FEB-9620-APR-96TAKE BACK RETURN
MAIL 5wM04SNyl0AnghCP2nx lAi
1 3370 3713 810210.96 .1.02NO29-MAR-9605-MAR-9631-JAN-96TAKE BACK RETURN
REG AIRSQC2C 5PNCy4mM
1 5214 46542831197.88.09.06NO21-APR-9630-MAR-9616-MAY-96NONE
AIR Om0L65CSAwSj5k6k
1 6564 6763246897.92.07.02NO30-MAY-9607-FEB-9603-FEB-96DELIVER IN PERSON
MAIL CB0SnyOL PQ32B70wB75k 6Aw10m0wh
1 7403 160524 31329.6 .1.04NO30-JUN-9614-MAR-9601 APR-96NONE
FOB C2gOQj OB6RLk1BS15 igN
2 8819 82012441659.44 0.08NO05-AUG-9609-FEB-9711-MAR-97COLLECT COD
AIR O52M70MRgRNnmm476mNm
3 9451 721230 41113.5.05.01AF05-SEP-9629-DEC-9318-FEB-94TAKE BACK RETURN
FOB 6wQnO0Llg6y
3 9717 1834440788.44.07.03RF09-NOV-9623-DEC-9315-FEB-94TAKE BACK RETURN
SHIP LhiA7wygz0k4g4zRhMLBAM
3 9844 1955 6 8066.64.04.01RF28-DEC-9615-DEC-9314-FEB-94TAKE BACK RETURN
REG AIR6nmBmjQkgiCyzCQBkxPPOx5j4hB 0lRywgniP1297
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo8.ctl;
— 验证数据;
— EXAMPLE9:加载CLOB列,为每个CLOB列准备一个文本文件;
— 创建测试表;
CREATE TABLE EMP
(
EMPNO NUMBER(4) not null,
ENAME CHAR(10),
JOB CHAR(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2),
RESUME CLOB
)
— 控制文件;
LOAD DATA
INFILE *
INTO TABLE EMP
REPLACE
FIELDS TERMINATED BY ‘,’
( EMPNO INTEGER EXTERNAL,
ENAME CHAR,
JOB CHAR,
MGR INTEGER EXTERNAL,
SAL DECIMAL EXTERNAL,
COMM DECIMAL EXTERNAL,
DEPTNO INTEGER EXTERNAL,
RES_FILE FILLER CHAR,
“RESUME” LOBFILE (RES_FILE) TERMINATED BY EOF NULLIF RES_FILE = ‘NONE’
)
BEGINDATA
7782,CLARK,MANAGER,7839,2572.50,,10,/u01/sqlldrdemo/demo91.dat
7839,KING,PRESIDENT,,5500.00,,10,/u01/sqlldrdemo/demo92.dat
7934,MILLER,CLERK,7782,920.00,,10,/u01/sqlldrdemo/demo93.dat
7566,JONES,MANAGER,7839,3123.75,,20,/u01/sqlldrdemo/demo94.dat
7499,ALLEN,SALESMAN,7698,1600.00,300.00,30,/u01/sqlldrdemo/demo95.dat
7654,MARTIN,SALESMAN,7698,1312.50,1400.00,30,/u01/sqlldrdemo/demo96.dat
7658,CHAN,ANALYST,7566,3450.00,,20,NONE
— 导入数据:sqlldr scott/tiger control=/u01/sqlldrdemo/demo9.ctl;
— 验证数据;
.png)
— EXAMPLE10:加载REF列和ARRAYs列;
— EXAMPLE11:转换字符集,使用Unicode编码加载数据;
————————- SQL*Loader的例子 ————————-
————————- 外部表 ORACLE_LOADER引擎的例子 ————————-
— 手动编写外部表语法;
1.创建DIRECTORY对象;
CREATE DIRECTORY ext_tab_dir AS ‘/u01/datafiles’;
SELECT * FROM dba_directories WHERE directory_name = ‘EXT_TAB_DIR’;
2.对用户授权;
GRANT READ, WRITE ON DIRECTORY ext_tab_dir TO hr;
SELECT * FROM dba_tab_privs WHERE table_name = ‘EXT_TAB_DIR’;
3.测试数据/u01/datafiles/emp.dat;
“56”, “baker”, “mary”, “f”, “01-09-2004”, “15-11-1980”
“87”, “roper”, “lisa”, “m”, “01-06-1999”, “20-12-1970”
4.创建外部表;
CREATE TABLE ext_tab_emp
(
ID INTEGER,
first_name VARCHAR2(20),
last_name VARCHAR2(20),
male CHAR(1),
birthday DATE,
hire_date DATE
)
ORGANIZATION EXTERNAL
(
TYPE ORACLE_LOADER
DEFAULT DIRECTORY ext_tab_dir
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE
BADFILE ‘EXT_TAB_DIR’:’emp.bad’
DISCARDFILE ‘EXT_TAB_DIR’:’emp.dis’
LOGFILE ‘EXT_TAB_DIR’:’emp.log’
FIELDS TERMINATED BY “,” OPTIONALLY ENCLOSED BY ‘”‘ LDRTRIM
REJECT ROWS WITH ALL NULL FIELDS
(
ID CHAR(20) TERMINATED BY “,” OPTIONALLY ENCLOSED BY ‘”‘,
first_name CHAR(20),
last_name CHAR(20),
male CHAR(1),
birthday CHAR(20) date_format DATE mask “DD-MM-YYYY”,
hire_date CHAR(20) date_format DATE mask “DD-MM-YYYY”
)
)
LOCATION (’emp.dat’, ’emp1.dat’)
) PARALLEL 2;
5.查看数据;
SELECT * FROM ext_tab_emp;
6.查看日志发现,如果使用并行的话会有多个线程同时工作,提高效率;
— 使用SQL*LOADER工具生成创建外部表的语法;
1.测试数据/u01/datafiles/car.dat;
Talbot,8/18,4,01-MAR-1923,ohv,8,295.00
Talbot,10/23,4,12-MAR-1923,ohv,8.9,375.00
Talbot,12/30,6,23-JAN-1924,ohv,13.4,550.00
Sunbeam,14/40,4,06-MAR-1924,ohv,13.9,895.00
Sunbeam,12/30,4,08-FEB-1924,ohv,11.5,570.00
Sunbeam,20/60,6,24-FEB-1924,ohv,20.9,950.00
Sunbeam,Twin Cam,6,11-MAR-1926,ohv,20.9,1125.00
Sunbeam,20,6,15-JUN-1927,ohv,20.9,750.00
Sunbeam,16,6,10-SEP-1927,ohv,16.9,550.00
Peugeot,172,4,28-SEP-1928,sv,6.4,165.00
Austin,7,4,29-JAN-1922,sv,7.2,225.00
Austin,12,4,01-JAN-1922,sv,12.8,550.00
Austin,20,4,04-JAN-1916,sv,22.4,616.00
Lanchester,40,6,08-JAN-1919,ohv,38.4,1875.00
Lanchester,21,6,16-JAN-1924,ohv,20.6,950.00
Vauxhall,30/98,4,18-JAN-1919,sv,23.8,1475.00
Vauxhall,23/60,4,27-JAN-1919,sv,22.4,1300.00
2.hr用户下的表结构;
3.控制文件/u01/datafiles/car.ctl;
LOAD DATA
INFILE ‘/u01/datafiles/car.dat’
BADFILE ‘/u01/datafiles/car.bad’
DISCARDFILE ‘/u01/datafiles/car.dsc’
APPEND
INTO TABLE car
FIELDS TERMINATED BY “,”
TRAILING NULLCOLS
(maker,
model,
no_cyl,
first_built_date,
engine,
hp,
price)
4.生成创建外部表的脚本;
sqlldr hr/hr control=/u01/datafiles/car.ctl external_table=GENERATE_ONLY;
5.适当修改即可;
conn hr/hr
CREATE TABLE car_ext
(
“MAKER” VARCHAR2(20),
“MODEL” VARCHAR2(20),
“NO_CYL” NUMBER,
“FIRST_BUILT_DATE” DATE,
“ENGINE” VARCHAR2(20),
“HP” NUMBER(10,1),
“PRICE” NUMBER(10,2)
)
ORGANIZATION external
(
TYPE oracle_loader
DEFAULT DIRECTORY EXT_TAB_DIR — 必须大写
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII
BADFILE ‘EXT_TAB_DIR’:’car.bad’
DISCARDFILE ‘EXT_TAB_DIR’:’car.dsc’
LOGFILE ‘EXT_TAB_DIR’:’car.log’
READSIZE 1048576
FIELDS TERMINATED BY “,” LDRTRIM
MISSING FIELD VALUES ARE NULL
REJECT ROWS WITH ALL NULL FIELDS
(
“MAKER” CHAR(255) TERMINATED BY “,”,
“MODEL” CHAR(255) TERMINATED BY “,”,
“NO_CYL” CHAR(255) TERMINATED BY “,”,
“FIRST_BUILT_DATE” CHAR(255) TERMINATED BY “,”,
“ENGINE” CHAR(255) TERMINATED BY “,”,
“HP” CHAR(255) TERMINATED BY “,”,
“PRICE” CHAR(255) TERMINATED BY “,”
)
)
location
(
‘car.dat’
)
)REJECT LIMIT UNLIMITED;
————————- 外部表 ORACLE_LOADER引擎的例子 ————————-
————————- 外部表 ORACLE_DATAPUMP引擎的例子 ————————-
— 卸载数据;
1.目标:卸载执行查询结果集的数据,并创建外部表;
conn hr/hr;
SELECT e.first_name, e.last_name, e.email, e.phone_number, d.department_name FROM EMPLOYEES e INNER JOIN DEPARTMENTS d ON e.department_id = d.department_id;
2.创建目录并授权;
CREATE DIRECTORY EXT_TAB_DIR AS ‘/u01/datafiles’;
GRANT READ, WRITE ON DIRECTORY EXT_TAB_DIR TO hr;
3.把数据导出为EMP_DEPT.dmp文件,创建外部表;
conn hr/hr;
CREATE TABLE emp_dept_ext
ORGANIZATION EXTERNAL
(
TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY EXT_TAB_DIR LOCATION (‘EMP_DEPT.dmp’)
)
AS
SELECT e.first_name, e.last_name, e.email, e.phone_number, d.department_name FROM EMPLOYEES e INNER JOIN DEPARTMENTS d ON e.department_id = d.department_id;
— 导入数据;
目标:把导出的数据导入到hr用户下t1表中;
conn hr/hr;
CREATE TABLE t1
(
FIRST_NAME VARCHAR2(20),
LAST_NAME VARCHAR2(25),
EMAIL VARCHAR2(25),
PHONE_NUMBER VARCHAR2(20),
DEPARTMENT_NAME VARCHAR2(30)
)
ORGANIZATION EXTERNAL
(
TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY EXT_TAB_DIR
LOCATION (‘EMP_DEPT.dmp’)
);
————————- 外部表 ORACLE_DATAPUMP引擎的例子 ————————-
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)